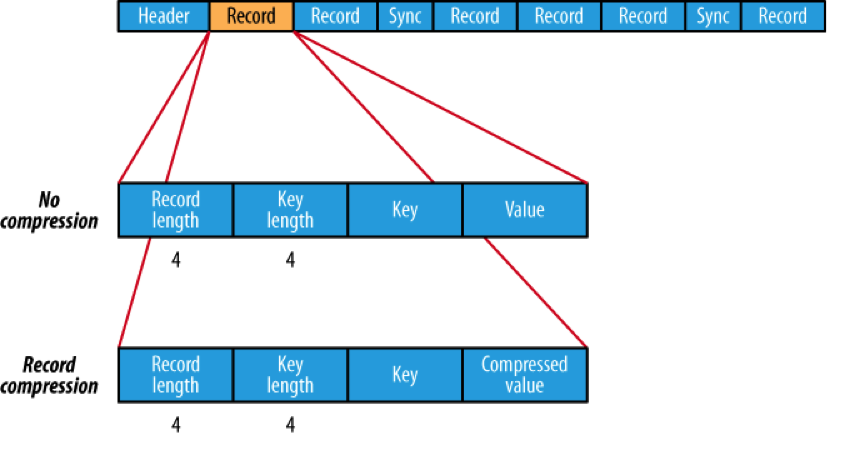
Hadoop 中的文件格式1 SequenceFileSequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。如果你用Java API 编写SequenceFile,并让Hive 读取的话,请确保使用value字段存放数据,否则你需要自定义读取这种SequenceFile 的InputFormat class 和OutputFormat class。
图1:Sequencefile 文件结构
2 RCFile
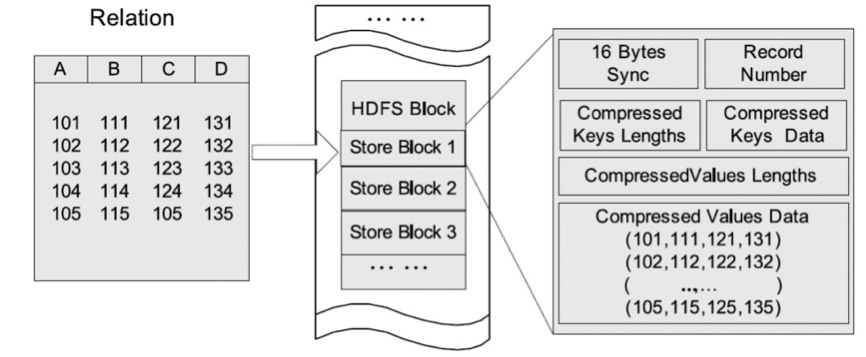
RCFile是Hive推出的一种专门面向列的数据格式。 它遵循“先按列划分,再垂直划分”的设计理念。当查询过程中,针对它并不关心的列时,它会在IO上跳过这些列。需要说明的是,RCFile在map阶段从 远端拷贝仍然是拷贝整个数据块,并且拷贝到本地目录后RCFile并不是真正直接跳过不需要的列,并跳到需要读取的列, 而是通过扫描每一个row group的头部定义来实现的,但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
图2:RCFile 文件结构
3 Avro
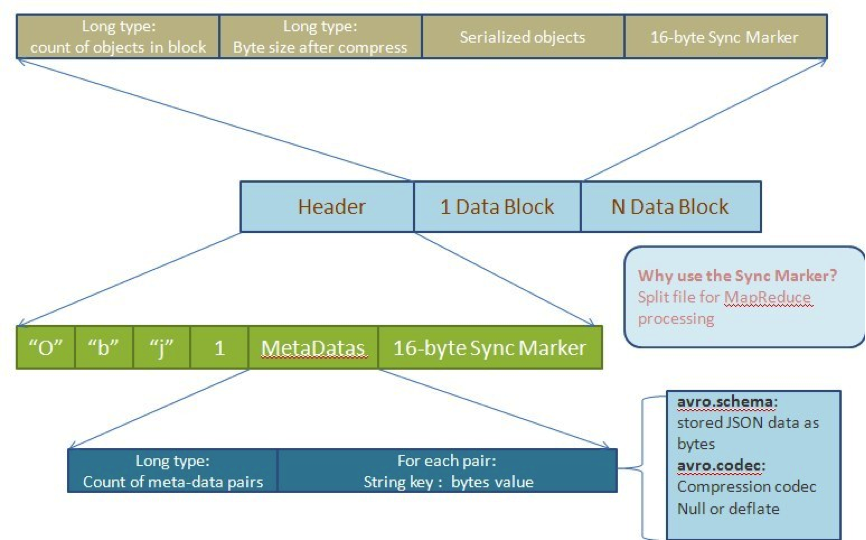
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且 Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。
图3:Avro MR 文件格式
4. 文本格式
除上面提到的3种二进制格式之外,文本格式的数据也是Hadoop中经常碰到的。如TextFile 、XML和JSON。 文本格式除了会占用更多磁盘资源外,对它的解析开销一般会比二进制格式高几十倍以上,尤其是XML 和JSON,它们的解析开销比Textfile 还要大,因此强烈不建议在生产系统中使用这些格式进行储存。 如果需要输出这些格式,请在客户端做相应的转换操作。 文本格式经常会用于日志收集,数据库导入,Hive默认配置也是使用文本格式,而且常常容易忘了压缩,所以请确保使用了正确的格式。另外文本格式的一个缺 点是它不具备类型和模式,比如销售金额、利润这类数值数据或者日期时间类型的数据,如果使用文本格式保存,由于它们本身的字符串类型的长短不一,或者含有 负数,导致MR没有办法排序,所以往往需要将它们预处理成含有模式的二进制格式,这又导致了不必要的预处理步骤的开销和储存资源的浪费。
5. 外部格式
Hadoop实际上支持任意文件格式,只要能够实现对应的RecordWriter和RecordReader即可。其中数据库格式也是会经常储存在 Hadoop中,比如Hbase,Mysql,Cassandra,MongoDB。 这些格式一般是为了避免大量的数据移动和快速装载的需求而用的。他们的序列化和反序列化都是由这些数据库格式的客户端完成,并且文件的储存位置和数据布局 (Data Layout)不由Hadoop控制,他们的文件切分也不是按HDFS的块大小(blocksize)进行切割。
文件存储大小比较与分析
我们选取一个TPC-H标准测试来说明不同的文件格式在存储上的开销。因为此数据是公开的,所以读者如果对此结果感兴趣,也可以对照后面的实验自行 做一遍。Orders 表文本格式的原始大小为1.62G。 我们将其装载进Hadoop 并使用Hive 将其转化成以上几种格式,在同一种LZO 压缩模式下测试形成的文件的大小。
表1:不同格式文件大小对比 从上述实验结果可以看到,SequenceFile无论在压缩和非压缩的情况下都比 原始纯文本TextFile大,其中非压缩模式下大11%, 压缩模式下大6.4%。这跟SequenceFile的文件格式的定义有关: SequenceFile在文件头中定义了其元数据,元数据的大小会根据压缩模式的不同略有不同。一般情况下,压缩都是选取block 级别进行的,每一个block都包含key的长度和value的长度,另外每4K字节会有一个sync-marker的标记。对于TextFile文件格 式来说不同列之间只需要用一个行间隔符来切分,所以TextFile文件格式比SequenceFile文件格式要小。但是TextFile 文件格式不定义列的长度,所以它必须逐个字符判断每个字符是不是分隔符和行结束符。因此TextFile 的反序列化开销会比其他二进制的文件格式高几十倍以上。 RCFile 文件格式同样也会保存每个列的每个字段的长度。但是它是连续储存在头部元数据块中,它储存实际数据值也是连续的。另外RCFile 会每隔一定块大小重写一次头部的元数据块(称为row group,由hive.io.rcfile.record.buffer.size控制,其默认大小为4M),这种做法对于新出现的列是必须的,但是如 果是重复的列则不需要。RCFile 本来应该会比SequenceFile 文件大,但是RCFile 在定义头部时对于字段长度使用了Run Length Encoding进行压缩,所以RCFile 比SequenceFile又小一些。Run length Encoding针对固定长度的数据格式有非常高的压缩效率,比如Integer、Double和Long等占固定长度的数据类型。在此提一个特例—— Hive 0.8引入的TimeStamp 时间类型,如果其格式不包括毫秒,可表示为”YYYY-MM-DD HH:MM:SS”,那么就是固定长度占8个字节。如果带毫秒,则表示为”YYYY-MM-DD HH:MM:SS.fffffffff”,后面毫秒的部分则是可变的。 Avro 文件格式也按group进行划分。但是它会在头部定义整个数据的模式(Schema), 而不像RCFile那样每隔一个row group就定义列的类型,并且重复多次。另外,Avro在使用部分类型的时候会使用更小的数据类型,比如Short或者Byte类型,所以Avro的数 据块比RCFile 的文件格式块更小。 序列化与反序列化开销分析我们可以使用Java的profile工具来查看Hadoop 运行时任务的CPU和内存开销。以下是在Hive 命令行中的设置: hive>set mapred.task.profile=true; hive>set mapred.task.profile.params =-agentlib:hprof=cpu=samples,heap=sites, depth=6,force=n,thread=y,verbose=n,file=%s 当map task 运行结束后,它产生的日志会写在$logs/userlogs/job-<jobid> 文件夹下。当然,你也可以直接在JobTracker的Web界面的logs或jobtracker.jsp 页面找到日志。 我们运行一个简单的SQL语句来观察RCFile 格式在序列化和反序列化上的开销: hive> select O_CUSTKEY,O_ORDERSTATUS from orders_rc2 where O_ORDERSTATUS=’P'; 其中的O_CUSTKEY列为integer类型,O_ORDERSTATUS为String类型。在日志输出的最后会包含内存和CPU 的消耗。 下表是一次CPU 的开销:
表2:一次CPU的开销 总结
转载请保留固定链接: https://linuxeye.com/Linux/553.html |