TCMalloc要比glibc 2.3的malloc(可以从一个叫作ptmalloc2的独立库获得)和其他我测试过的malloc都快。ptmalloc在一台2.8GHz的P4机 器上(对于小对象)执行一次malloc及free大约需要300纳秒。而TCMalloc的版本同样的操作大约只需要50纳秒。malloc版本的速度 是至关重要的,因为如果malloc不够快,应用程序的作者就很有可能在malloc之上写一个自己的自由列表。这就可能导致额外的代码复杂度,以及更多 的内存占用――除非作者本身非常仔细地划分自由列表的大小并经常从自由列表中清除空闲的对象。 TCMalloc也减少了多线程程序中的锁争用情况。对于小对象,几乎已经达到了零争用。对于大对象,TCMalloc尝试使用粒度较好和有效的自旋锁。 ptmalloc同样是通过使用每线程各自的场地来减少锁争用,但是ptmalloc2使用每线程场地有一个很大的问题。在ptmalloc2中,内存可 能会从一个场地移动到另一个。这有可能导致大量空间被浪费。例如,在一个Google的应用中,第一阶段可能会为其URL标准化的数据结构分配大约 300MB内存。当第一阶段结束后,第二阶段将从同样的地址空间开始。如果第二个阶段被安排到了一个与第一阶段什?用的场地不同的场地,这个阶段不会复用 任何第一阶段留下的的内存,并会给地址空间添加另外一个300MB。类似的内存爆炸问题也可以在其他的应用中看到。 TCMalloc的另一个好处是小对象的空间最优表现形式。例如,分配N个8字节对象可能要使用大约8N * 1.01字节的空间。即,多用百分之一的空间。而ptmalloc2中每个对象都使用了一个四字节的头,(我认为)并将最终的尺寸规整为8字节的倍数,最 后使用了16N字节。 使用 要使用TCMalloc,只要将tcmalloc通过“-ltcmalloc”链接器标志接入你的应用即可。 你也可以通过使用LD_PRELOAD在不是你自己编译的应用中使用tcmalloc: $ LD_PRELOAD="/usr/lib/libtcmalloc.so"LD_PRELOAD比较讨巧,我们也不十分推荐这种用法。 TCMalloc还包含了一个堆检查器以及一个堆测量器。 如果你更想链接不包含堆测量器和检查器的TCMalloc版本(比如可能为了减少静态二进制文件的大小),你可以接入 libtcmalloc_minimal。概览 TCMalloc给每个线程分配了一个线程局部缓存。小分配可以直接由线程局部缓存来满足。需要的话,会将对象从中央数据结构移动到线程局部缓存中,同时定期的垃圾收集将用于把内存从线程局部缓存迁移回中央数据结构中。 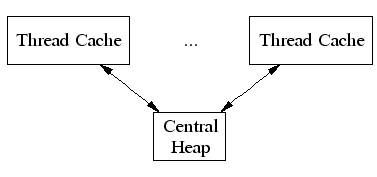 32K的对象(“小”对象)和大对象区分开来。大对象直接使用页级分配器(一个页是一个4K的对齐内存区域)从中央堆直接分配。即,一个大对象总是页对齐的并占据了整数个数的页。 连续的一些页面可以被分割为一系列小对象,而他们的大小都相同。例如,一个连续的页面(4K)可以被划分为32个128字节的对象。 小对象的分配 每个小对象的大小都会被映射到170个可分配的尺寸类别中的一个。例如,在分配961到1024字节时,都会归整为1024字节。尺寸类别这样隔 开:较小的尺寸相差8字节,较大的尺寸相差16字节,再大一点的尺寸差32字节,如此类推。最大的间隔(对于尺寸 >= ~2K的)是256字节。 一个线程缓存对每个尺寸类都包含了一个自由对象的单向链表。 当分配一个小对象时:
如果自由列表为空:
大对象的分配 一个大对象的尺寸(> 32K)会被除以一个页面尺寸(4K)并取整(大于结果的最小整数),同时是由中央页面堆来处理的。中央页面堆又是一个自由列表的阵列。对于 i < 256而言,第k个条目是一个由k个页面组成的自由列表。第256个条目则是一个包含了长度>= 256个页面的自由列表:
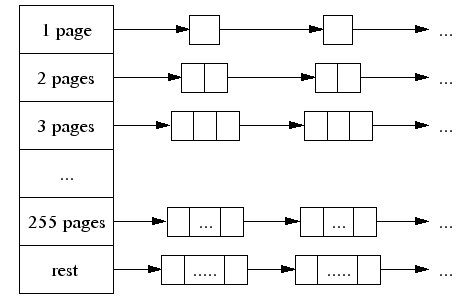 如果k个页面的一次分配行为由连续的长度> k的页面满足了,剩下的连续页面将被重新插回到页面堆的对应的自由列表中。 跨度(Span) TCMalloc 管理的堆由一系列页面组成。连续的页面由一个“跨度”(Span)对象来表示。一个跨度可以是已被分配或者是自由的。如果是自由的,跨度则会是一个页面堆 链表中的一个条目。如果已被分配,它会是一个已经被传递给应用程序的大对象,或者是一个已经被分割成一系列小对象的一个页面。如果是被分割成小对象的,对 象的尺寸类别会被记录在跨度中。 由页面号索引的中央数组可以用于找到某个页面所属的跨度。例如,下面的跨度a占据了2个页面,跨度b占据了1个页面,跨度c占据了5个页面最后跨度d占据了3个页面。 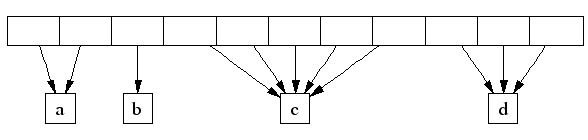 在一个32位的地址空间中,中央阵列由一个2层的基数树来表示,其中根包含了32个条目,每个叶包含了 215个条目(一个32为地址空间包含了 220个 4K 页面,所以这里树的第一层则是用25整除220个页面)。这就导致了中央阵列的初始内存使用需要128KB空间(215*4字节),看上去还是可以接受的。 在64位机器上,我们将使用一个3层的基数树。 解除分配 当一个对象被解除分配时,我们先计算他的页面号并在中央阵列中查找对应的跨度对象。该跨度会告诉我们该对象是大是小,如果它是小对象的话尺寸类别是 什么。如果是小对象的话,我们将其插入到当前线程的线程缓存中对应的自由列表中。如果线程缓存现在超过了某个预定的大小(默认为2MB),我们便运行垃圾 收集器将未使用的对象从线程缓存中移入中央自由列表。 如果该对象是大对象的话,跨度会告诉我们该对象覆盖的页面的范围。假设该范围是[p,q]。我们还会查找页面p-1和页面q+1对应的跨度。如果这两个相邻的跨度中有任何一个是自由的,我们将他们和[p,q]的跨度接合起来。最后跨度会被插入到页面堆中合适的自由列表中。 小对象的中央自由列表 就像前面提过的一样,我们为每一个尺寸类别设置了一个中央自由列表。每个中央自由列表由两层数据结构来组成:一系列跨度和每个跨度一个自由对象的链表。 通过从某个跨度中移除第一个条目来从中央自由列表分配一个对象。(如果所有的跨度里只有空链表,那么首先从中央页面堆中分配一个尺寸合适的跨度。) 一个对象可以通过将其添加到他包含的跨度的链表中来返回到中央自由列表中。如果链表长度现在等于跨度中所有小对象的数量,那么该跨度就是完全自由的了,就会被返回到页面堆中。 线程缓存的垃圾收集 某个线程缓存当缓存中所有对象的总共大小超过2MB的时候,会对他进行垃圾收集。垃圾收集阈值会自动根据线程数量的增加而减少,这样就不会因为程序有大量线程而过度浪费内存。 我们会遍历缓存中所有的自由列表并且将一定数量的对象从自由列表移到对于得中央列表中。 从某个自由列表中移除的对象的数量是通过使用一个每列表的低水位线L 来确定的。L记录了自上一次垃圾收集以来列表最短的长度。注意,在上一次的垃圾收集中我们可能只是将列表缩短了L个对象而没有对中央列表进行任何额外访 问。我们利用这个过去的历史作为对未来访问的预测器并将L/2个对象从线程缓存自由列表中移到相应的中央自由列表中。这个算法有个很好的特性是,如果某个 线程不再使用某个特定的尺寸时,该尺寸的所有对象都会很快从线程缓存被移到中央自由列表,然后可以被其他缓存利用。 性能备注 PTMalloc2单元测试 PTMalloc2包(现在已经是glibc的一部分了)包含了一个单元测试程序t-test1.c。它会产生一定数量的线程并在每个线程中进行一系列分配和解除分配;线程之间没有任何通信除了在内存分配器中同步。 t- test1(放在tests/tcmalloc/中,编译为ptmalloc_unittest1) 用一系列不同的线程数量(1~20)和最大分配尺寸(64B~32KB)运行。这些测试运行在一个2.4GHz 双核心Xeon的RedHat 9系统上,并启用了超线程技术, 使用了Linux glibc-2.3.2,每个测试中进行一百万次操作。在每个案例中,一次正常运行,一次使用LD_PRELOAD=libtcmalloc.so。 下面的图像显示了TCMalloc对比PTMalloc2在不同的衡量指标下的性能。首先,现实每秒全部操作(百万)以及最大分配尺寸,针对不同数量的线程。用来生产这些图像的原始数据(time工具的输出)可以在t-test1.times.txt中找到。 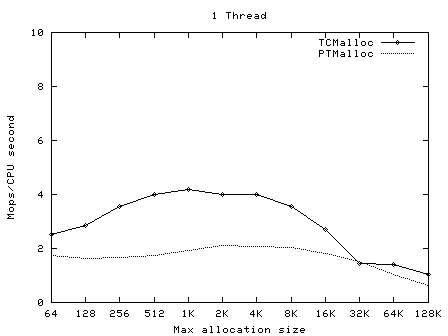 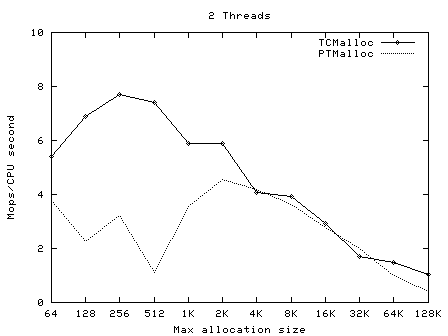 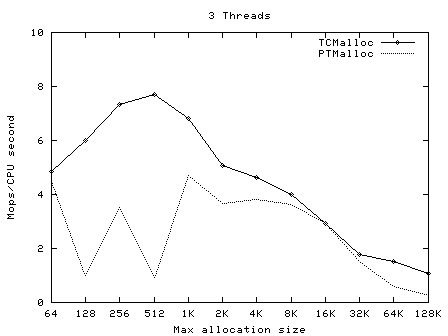 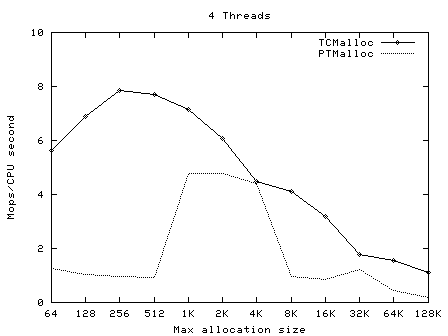 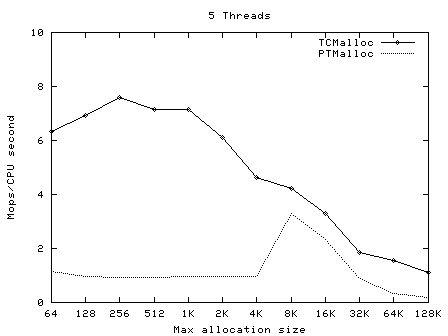 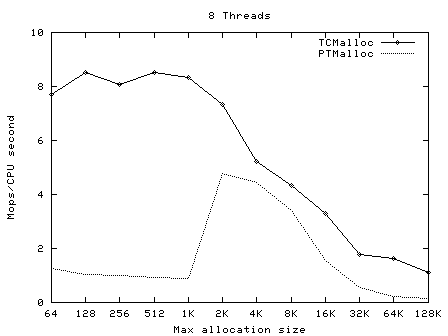 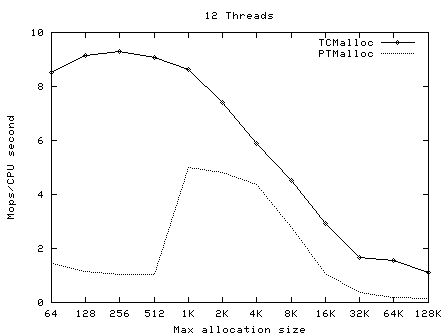 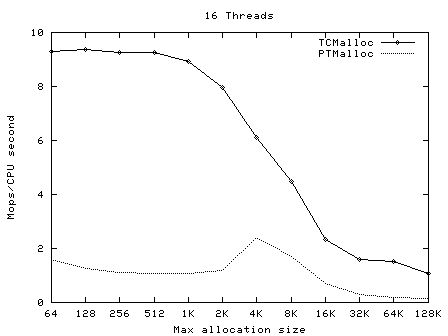 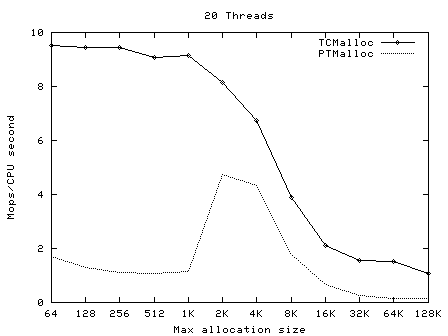 这次我们再一次看到TCMalloc要比PTMalloc2更连续也更高效。对于<32K的最大分配尺寸,TCMalloc在大线程数的情况 下典型地达到了CPU时间每秒约0.5~1百万操作,同时PTMalloc通常达到了CPU时间每秒约0.5~1百万,还有很多情况下要比这个数字小很 多。在32K最大分配尺寸之上,TCMalloc下降到了每CPU时间秒1~1.5百万操作,同时PTMalloc对于大线程数降到几乎只有零(也就是, 使用PTMalloc,在高度多线程的情况下,很多CPU时间被浪费在轮流等待锁定上了)。 转自:http://shiningray.cn/tcmalloc-thread-caching-malloc.html 转载请保留固定链接: https://linuxeye.com/Linux/1912.html |