对应的文件为: D:/mysql-5.1.7-beta/storage/innobase/include/ut0lst.h 1)常用结构体 Alex:“bingxi,考你一个问题:如果共享空间有4个文件,这四个文件是如何连在一起的。我们在ut0lst.h中看到了这样一段注释: Bingxi:“要掌握这个具体怎么实现,我们还是需要进行调试。在调试之前,我们先从这段文字中看出几个有用的信息,然后再去验证它。1)这是一个双向链表,因此插入的时候有prev和next指针,2)一个结构体可能会属于多个list。 我们先来验证这两个信息。看fil_node_struct的定义,该结点属于两个list,一个对应的是文件list,另外一个是LURlist。 Alex:“ok,这个我们就来debug一下。debug之前我们要先看下,file_space_struct中的一个结构成员:chain。共享表空间对应的4个文件会挂在上面,然后每个file_node_t结构通过prev和next进行双向连接。 我们接着通过debug进行验证,配置my.ini(本例路径为D:/mysql-5.1.7-beta/my.ini,也可以存放在其它路径)。修改表空间,使用共享表空间为4个文件: 在fil_node_create函数设置断点,每执行一次看一次成员变量,等共享表空间对应的4个文件都执行之后我们可以看下该space对应的chain对应的取值。见图1: 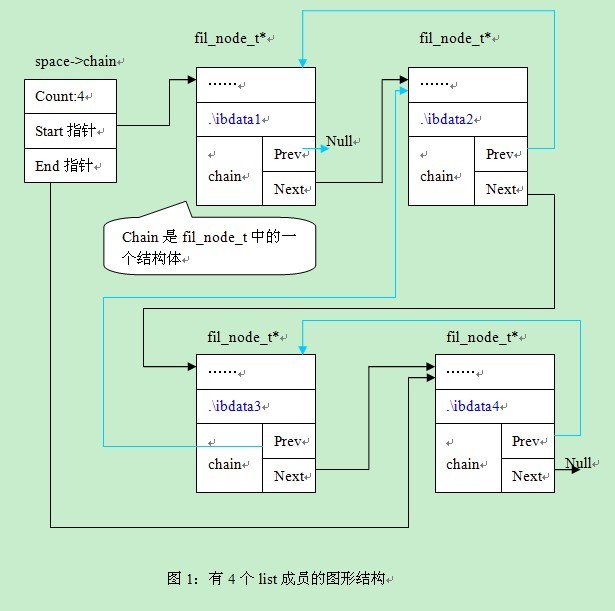 从图1中,我们可以看出4个结点通过prev及next指针相连,通过space->chain我们可以找到第一个结点,和最后一个结点。在图形中,通过天蓝色的线条表示prev。 通过这样的一个图形,我们会对list的表达方式有一个整体的了解。下面我们,在看一些具体函数的实现方式。 2)常用的函数 Bingxi:“好的,我们来看下插入函数吧。在图1中,我有一个疑问,问什么第一个成员的prev指向的是null,而不是指向space。” Alex:“赞同,我们还是通过刚刚的例子来看下常用的插入函数UT_LIST_ADD_LAST,这个函数是往链表的末尾插入一个值。我们先看下该函数的定义,先不看其中的实现: Alex:“有时候,这样的方法也挺有效的,呵呵。第一次使用的时候可以用这样的方法先理解下,然后再看会简单些。我们现在直接看下类似的插入到链表首的宏的实现,这次我们直接看,不用代入法。 Bingxi:“这两个宏就不用看了吧,都是些链表的算法。留给大家自己看下吧。除了这两个宏之外,还有三个最基本的宏,用于获取base_node的三个成员:count、start、end。这里我把定义贴一下: Bingxi:“好的,我回去想一下,第十篇出来后,就给你提供一个list,列出段、簇、页、记录等等的物理存储格式以及相互关系,然后按照list的组织方式来往下思考。” Alex:“ok” 转载请保留固定链接: https://linuxeye.com/database/379.html |