MySQL/InnoDB的加锁分析,一直是一个比较困难的话题。我在工作过程中,经常会有同事咨询这方面的问题。同时,微博上也经常会收到MySQL锁相关的私信,让我帮助解决一些死锁的问题。本文,准备就MySQL/InnoDB的加锁问题,展开较为深入的分析与讨论,主要是介绍一种思路,运用此思路,拿到任何一条SQL语句,都能完整的分析出这条语句会加什么锁?会有什么样的使用风险?甚至是分析线上的一个死锁场景,了解死锁产生的原因。 注:MySQL是一个支持插件式存储引擎的数据库系统。本文下面的所有介绍,都是基于InnoDB存储引擎,其他引擎的表现,会有较大的区别。 MVCC:Snapshot Read vs Current Read MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)。MVCC最大的好处,相信也是耳熟能详:读不加锁,读写不冲突。在读多些少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,这也是为什么现阶段,几乎所有的RDBMS,都支持了MVCC。 在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。 在一个支持MVCC并发控制的系统中,哪些读操作是快照读?哪些操作又是当前读呢?以MySQL InnoDB为例: 快照读:简单的select操作,属于快照读,不加锁。(当然,也有例外,下面会分析)
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
所有以上的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁 (排它锁)。 为什么将 插入/更新/删除 操作,都归为当前读?可以看看下面这个 更新 操作,在数据库中的执行流程: 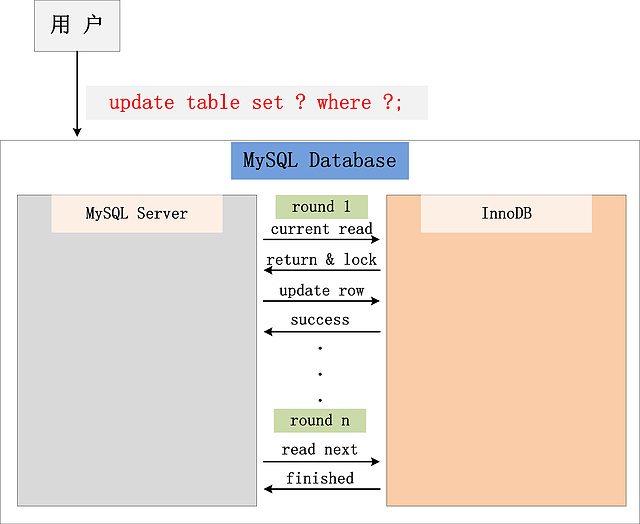 注:根据上图的交互,针对一条当前读的SQL语句,InnoDB与MySQL Server的交互,是一条一条进行的,因此,加锁也是一条一条进行的。先对一条满足条件的记录加锁,返回给MySQL Server,做一些DML操作;然后在读取下一条加锁,直至读取完毕。 Cluster Index:聚簇索引 InnoDB存储引擎的数据组织方式,是聚簇索引表:完整的记录,存储在主键索引中,通过主键索引,就可以获取记录所有的列。关于聚簇索引表的组织方式,可以参考MySQL的官方文档:Clustered and Secondary Indexes 。本文假设读者对这个,已经有了一定的认识,就不再做具体的介绍。接下来的部分,主键索引/聚簇索引 两个名称,会有一些混用,望读者知晓。 2PL:Two-Phase Locking 传统RDBMS加锁的一个原则,就是2PL (二阶段锁):Two-Phase Locking。相对而言,2PL比较容易理解,说的是锁操作分为两个阶段:加锁阶段与解锁阶段,并且保证加锁阶段与解锁阶段不相交。下面,仍旧以MySQL为例,来简单看看2PL在MySQL中的实现。 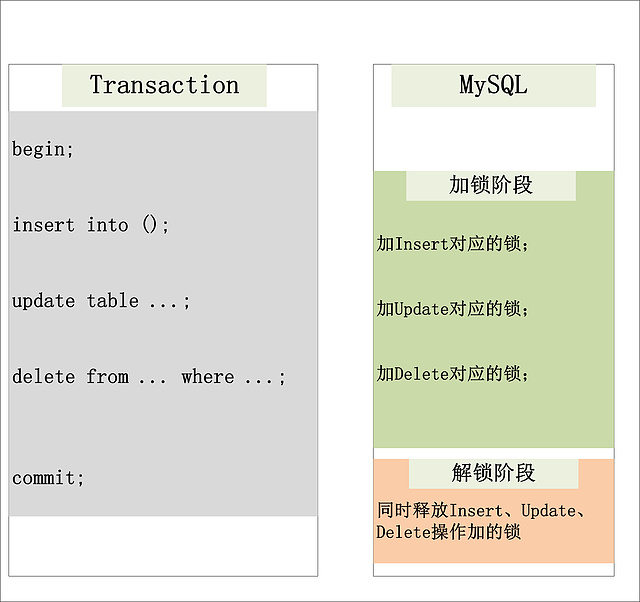 Isolation Level 隔离级别:Isolation Level,也是RDBMS的一个关键特性。相信对数据库有所了解的朋友,对于4种隔离级别:Read Uncommited,Read Committed,Repeatable Read,Serializable,都有了深入的认识。本文不打算讨论数据库理论中,是如何定义这4种隔离级别的含义的,而是跟大家介绍一下MySQL/InnoDB是如何定义这4种隔离级别的。 MySQL/InnoDB定义的4种隔离级别: Read Uncommited 可以读取未提交记录。此隔离级别,不会使用,忽略。 Read Committed (RC) 快照读忽略,本文不考虑。 针对当前读,RC隔离级别保证对读取到的记录加锁 (记录锁),存在幻读现象。 Repeatable Read (RR) 快照读忽略,本文不考虑。 针对当前读,RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。 Serializable 从MVCC并发控制退化为基于锁的并发控制。部分快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。 Serializable隔离级别下,读写冲突,因此并发度急剧下降,在MySQL/InnoDB下不建议使用。 一条简单SQL的加锁实现分析 在介绍完一些背景知识之后,本文接下来将选择几个有代表性的例子,来详细分析MySQL的加锁处理。当然,还是从最简单的例子说起。经常有朋友发给我一个SQL,然后问我,这个SQL加什么锁?就如同下面两条简单的SQL,他们加什么锁?
针对这个问题,该怎么回答?我能想象到的一个答案是:
这个答案对吗?说不上来。即可能是正确的,也有可能是错误的,已知条件不足,这个问题没有答案。如果让我来回答这个问题,我必须还要知道以下的一些前提,前提不同,我能给出的答案也就不同。要回答这个问题,还缺少哪些前提条件?
没有这些前提,直接就给定一条SQL,然后问这个SQL会加什么锁,都是很业余的表现。而当这些问题有了明确的答案之后,给定的SQL会加什么锁,也就一目了然。下面,我将这些问题的答案进行组合,然后按照从易到难的顺序,逐个分析每种组合下,对应的SQL会加哪些锁? 注:下面的这些组合,我做了一个前提假设,也就是有索引时,执行计划一定会选择使用索引进行过滤 (索引扫描)。但实际情况会复杂很多,真正的执行计划,还是需要根据MySQL输出的为准。
排列组合还没有列举完全,但是看起来,已经很多了。真的有必要这么复杂吗?事实上,要分析加锁,就是需要这么复杂。但是从另一个角度来说,只要你选定了一种组合,SQL需要加哪些锁,其实也就确定了。接下来,就让我们来逐个分析这9种组合下的SQL加锁策略。 注:在前面八种组合下,也就是RC,RR隔离级别下,SQL1:select操作均不加锁,采用的是快照读,因此在下面的讨论中就忽略了,主要讨论SQL2:delete操作的加锁。 组合一:id主键+RC 这个组合,是最简单,最容易分析的组合。id是主键,Read Committed隔离级别,给定SQL:delete from t1 where id = 10; 只需要将主键上,id = 10的记录加上X锁即可。如下图所示: 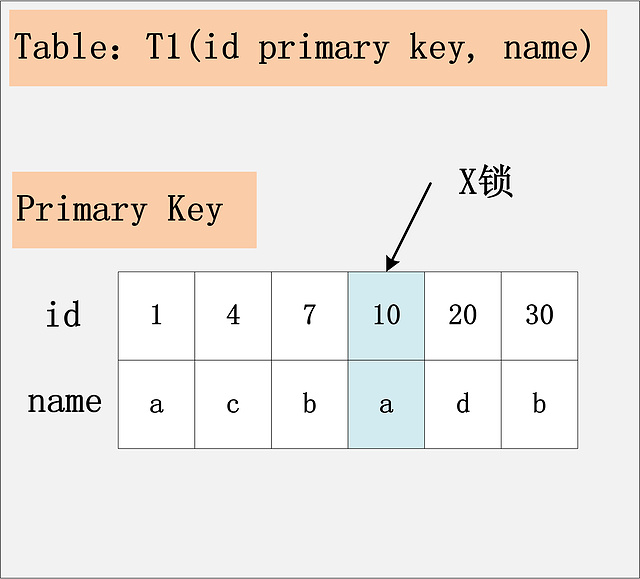 组合二:id唯一索引+RC 这个组合,id不是主键,而是一个Unique的二级索引键值。那么在RC隔离级别下,delete from t1 where id = 10; 需要加什么锁呢?见下图: 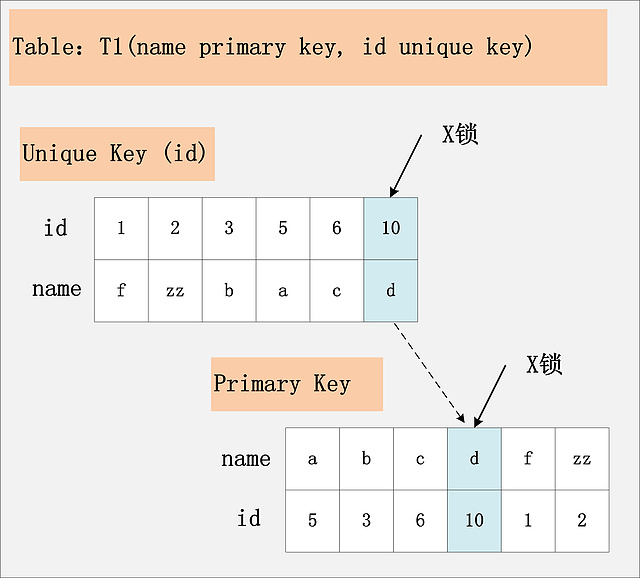 结论:若id列是unique列,其上有unique索引。那么SQL需要加两个X锁,一个对应于id unique索引上的id = 10的记录,另一把锁对应于聚簇索引上的[name='d',id=10]的记录。 组合三:id非唯一索引+RC 相对于组合一、二,组合三又发生了变化,隔离级别仍旧是RC不变,但是id列上的约束又降低了,id列不再唯一,只有一个普通的索引。假设delete from t1 where id = 10; 语句,仍旧选择id列上的索引进行过滤where条件,那么此时会持有哪些锁?同样见下图: 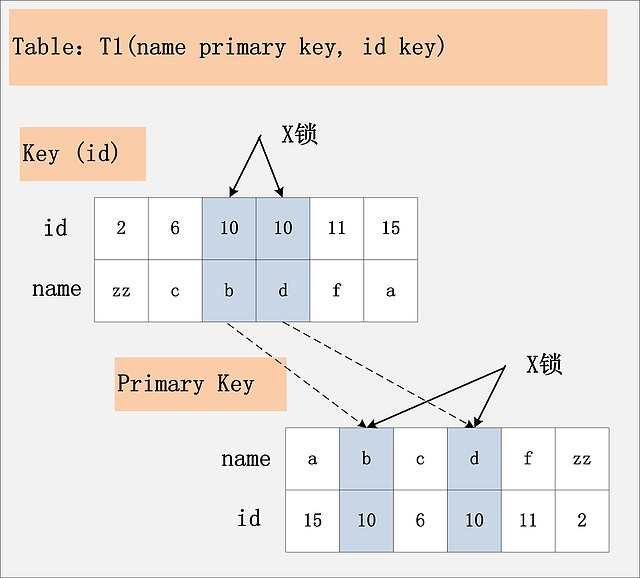 结论:若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。 组合四:id无索引+RC 相对于前面三个组合,这是一个比较特殊的情况。id列上没有索引,where id = 10;这个过滤条件,没法通过索引进行过滤,那么只能走全表扫描做过滤。对应于这个组合,SQL会加什么锁?或者是换句话说,全表扫描时,会加什么锁?这个答案也有很多:有人说会在表上加X锁;有人说会将聚簇索引上,选择出来的id = 10;的记录加上X锁。那么实际情况呢?请看下图: 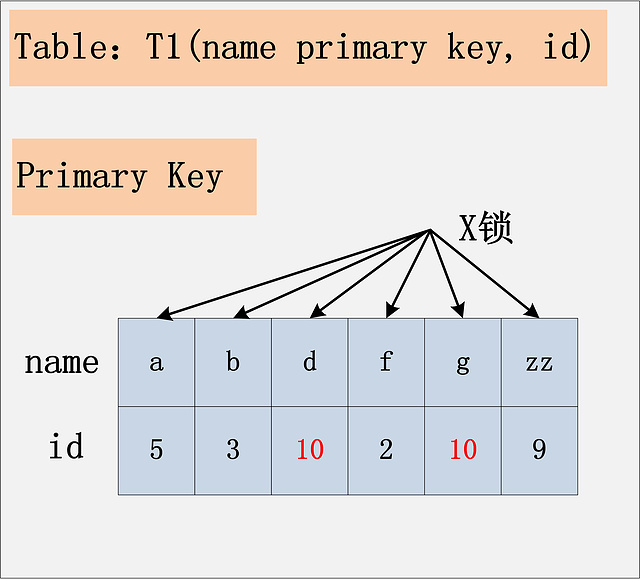 有人可能会问?为什么不是只在满足条件的记录上加锁呢?这是由于MySQL的实现决定的。如果一个条件无法通过索引快速过滤,那么存储引擎层面就会将所有记录加锁后返回,然后由MySQL Server层进行过滤。因此也就把所有的记录,都锁上了。 注:在实际的实现中,MySQL有一些改进,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁 (违背了2PL的约束)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。 结论:若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束。 原文:http://hedengcheng.com/?p=771 转载请保留固定链接: https://linuxeye.com/database/1986.html |