基于文档存储的MongoDB在处理非结构化数据时,相当的便捷。
每到年底,各大国企、政府机构都会拼命的花钱,拼命的采购,采购的东西呢,除了“低值易耗品”,就是“固定资产了”。碰巧几年前待过的一家公司,主打产品就 是“固定资产管理系统”,对相关业务有些许了解。索性,结合tiger留的讨论话题,改善一下系统某些地方的设计。其实固定资产的数据是挺大的,特别是当 一个市,一个省,或者是全国范围内统计的时候,印象当中,大概是四年一次全国范围内的核查。
本示例仅分析”固定资产明细表“的设计。“固定资产明细表”,假设需要大概包括以下字段:
|
编号 |
|
名称 |
|
型号 |
|
厂家 |
|
单价 |
|
数量 |
|
购买日期 |
|
详细参数与规格 |
“详细参数与规格”,是个很特殊的字段。因为每个种类的产品包含的参数与规格信息都是不一样的,并且不同型号的同种产品相差也可能很大。比如说,硬盘的参数主 要关注容量、尺寸、接口类型、转速等等等等。而路由器的参数则主要关注端口结构、网络标准、网络协议等等等等。“详细参数与规格”字段里存储的数据千差万 别,用个专业点的词来说,就是大量“非结构化数据”。
假设系统采用的是关系型数据库,简单的设计,“固定资产明细表”表设计如下:
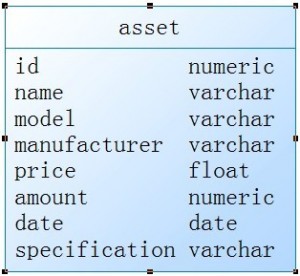
可以考虑将每个id对应的item的所有参数与规格信息作为一个大文本存储在specification字段中。也可以考虑将每个id对应的item的所有 参数与规格信息存储为一个独立的文本文件,然后specification存储文件的位置。或者可以考虑将每个id对应的item的所有参数与规格信息存 储为一个子表。
假设我们采取的方案是将每个id对应的item的所有参数与规格信息作为一个大文本存储在specification字段中。两条数据的结构大概为:
|
Id |
1 |
|
Name |
硬盘 |
|
Model |
ST1000DM003 |
|
manufacturer |
希捷 |
|
price |
500 |
|
amout |
200 |
|
date |
2012-12-21 |
|
specification |
硬盘容量:1T 接口类型:STAT3.0 转速:7200rpm … |
|
Id |
2 |
|
Name |
路由器 |
|
Model |
NE40-8 |
|
manufacturer |
华为 |
|
price |
150000 |
|
amout |
6 |
|
date |
2012-12-21 |
|
specification |
端口结构:模块化 网络协议:IEEE 802.1ad,IEEE 802.1d … |
这样做,虽然解决了数据存储的问题,但并没有真正的实现结构化存储,并且在后期的统计分析中无法利用specification字段,严格的说,是无法高效 利用。我们没办法高效针对“详细参数与规格”中的数据做统计分析。当然,可以通过采用在数据库中多加表、在表之间多加关系、在表中多加字段的方式存储这种 数据,或者说,利用oracle的全文索引机制在specification字段上建立全文索引。但是显然,这两种“曲线救国”的方式效率都不高。
我们现在改用MongoDB重构这个设计。
MongoDB 是一个基于分布式文件存储的数据库。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。MongoDB支持的查 询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
基于MongoDB设计的“固定资产明细”表asset,两条数据的结构大概如下:
|
Id |
Data
|
|
1 |
{
“mame”:”硬盘”,
“model”:” ST1000DM003″,
” manufacturer “:”希捷”,
“price”:500,
“amount”:200,
“date”:”2012-12-21″,
“specification”:
{
“端口结构”:”模块化”,
“接口类型”:”STAT3.0″,
“转速”:”7200rpm”
}
}
|
|
2 |
{
“mame”:”路由器”,
“model”:” NE40-8″,
” manufacturer “:”华为”,
“price”:150000,
“amount”:6,
“date”:”2012-12-21″,
“specification”:
{
“端口结构”:”模块化”,
“网络协议”:”IEEE 802.1ad,IEEE 802.1d”
}
}
|
利用MongoDB面向集合存储以及模式自由的特性,存储这种“非结构化数据”很容易。并且它提供了很强大的检索功能,我们可以很快度的查询想要的数据,例如,查询容量为1T的硬盘:
JDBC伪代码
…Mongo mongo = new Mongo();DB db = mongo.getDB(“db”);
DBcollection coll = db.getCollection(“asset”);
DBCursor cursor = coll.find({“asset.name”:”硬盘”,”asset.specification.容量”:”1T”});
…
同时,MongoDB也为我们提供了强大的Map/Reduce分布式机制。能够提高大规模数据计算的效率,并且可以部署到大规模的集群上运行。
|