以下是Will博客的全文翻译。 一个月之前,随着Digg v1的二度启动,历史似乎再一次回到原点。而我们对于Digg的记忆也随着四个月前Digg技术团队加入SocialCode而逐渐模糊。现在似乎是回顾 过去的最佳时机,让我们一起来看看从2010年5月到2012年5月,Digg.com是如何在杰出的系统及团队手中一步步构筑成形的。 本文无心涉及任何争论、也不打算渲染过多细节,我们要做的只是告诉大家自己的工作经历与所建立的架构。 团队结构、规模及组织方式 我们首先要介绍的是公司规模、团队组织方式以及一系列裁员、招聘给人员结构带来的影响,这算是必要的背景介绍。 出于文章核心话题的考虑,我不会讨论与销售、财务、广告管理、设计、人力资源、业务拓展团队等有关的内容;他们当然也是公司的重要组成部分、曾为企业带来不可磨灭的贡献,但这并不是本文要讨论的主题。
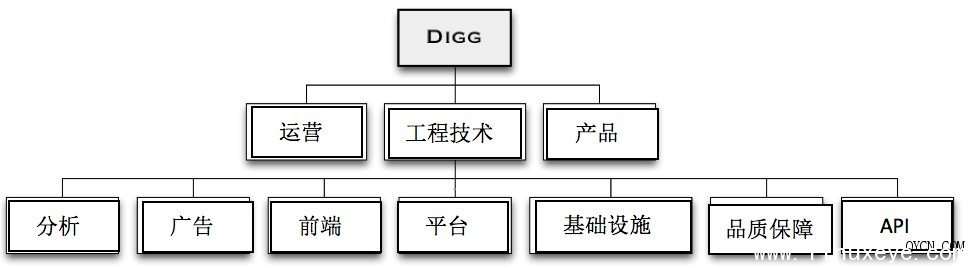
我们的故事从一套非常传统的企业布局开始,这里拥有特色鲜明的产品、工程技术及运营管理机制。产品团队规模很小,只有四名成员、运营团队则拥有大约八位工程师、品质保障部门有六位工程师、而开发团队则包含大约二十位开发人员。 开发团队本身的结构很单纯,包括四大横向部门(前端、API、平台以及基础设施)与两大纵向部门(广告和分析)。产品团队的运营工作由功能性划分、遵循纵向管理机制,协作方案则采用与各开发团队横向联合的方式。 在经历了数次裁员及集体离职的冲击之后,组织结构最终回归到极简化的初始状态。
在过去的一年中,我们的运营团队只有三位成员、工程技术团队有七位成员,而广告团队则有四位成员。 代码审查与持续部署 在处理核心开发实践的阶段,我们的工程师队伍一度扩张到四十人,但随后又缩减为十四人。现在我们来看看整个开发实践流程,包括如何处理合并工作、审查并部署代码。
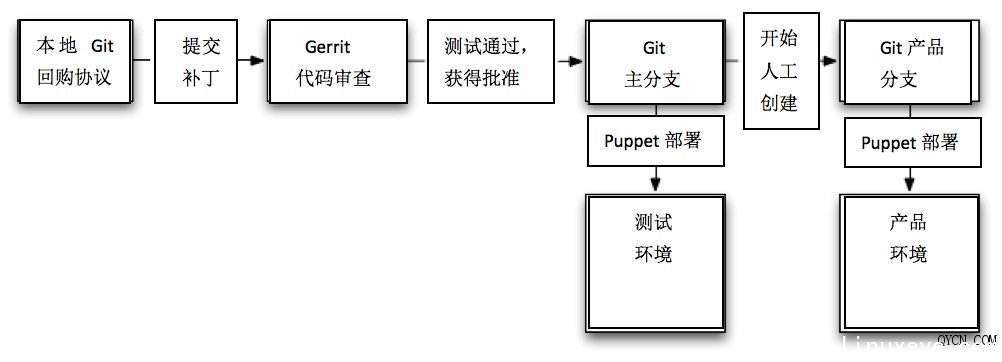
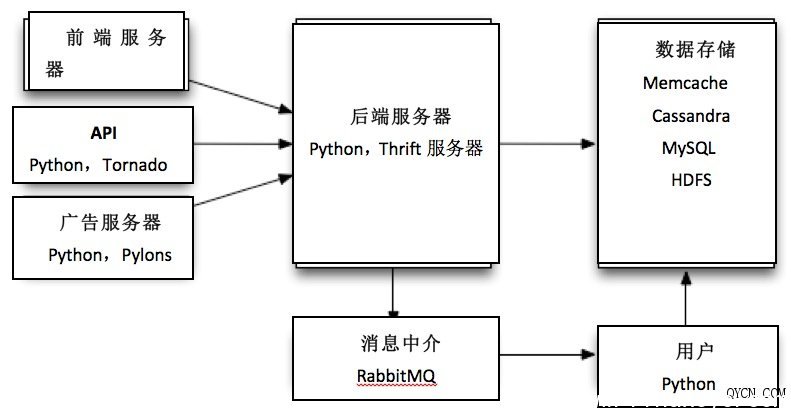
现在具体阐述以上流程图所表达的信息: 1. 我们使用Git作为源代码控制工具,使用Gerrit作为代码审查工具。每一段代码都需要接受审查并获得批准,同时必须通过所有单元测试。 2. 每当有补丁集被提交至Gerrit做代码审查,Jenkins都会自动运行其单元测试流程,并在测试结束后将成功或者失败结果递交Gerrit作为审查依据。 也就是说,代码审查人员不必在那些被自动流程检测出问题的补丁身上浪费时间。这同时意味着我们从来不会把那些无法通过单元测试的残缺代码合并到Git资源库当中。 3. 一旦补丁集通过了Gerrit测试并获得代码审查人员的批准,这些代码就会被合并到Git主分支当中,并通过Puppet以自动化形式部署到测试环境 下。在顺利部署到测试环境下并成功通过了集成在该环境中的测试流程后,这些新的补丁集就会被合并到Git中的产品分支里。 4. 我们以手动方式处理Jenkins工作并部署至产品环境,更新代码的部署工作则由Puppet负责。 接下来我们着手进行产品的持续部署,但在经历了几次严重的部署事故之后,我们决定委派专项人员处理这类工作,直到确认所有产品化流程都完全达到我们的预定效果。 如果遇上不得不采取持续部署的情况,我们决定进一步改善自己的测试机制,以保证尽量不让问题漏网。但这么做有点事倍功半,我们其实没那么多时间做这些繁琐的工作。 在我看来,这套审查、测试及代码部署系统堪称Digg项目成功的最大功臣,同时也是代码部署工作的一大建设性突破。它的结构非常科学,足以在保证代码标准的同时承受技术团队由四十人缩减为十四人所带来的人力匮乏。 应急流程与实践 我们零零散散采用过很多实践方案,但大多数都是被现状推着走,而不是提前做好了充分准备。 1. 刚开始我们将单元测试的覆盖率定得非常高,但随着团队规模的萎缩,我们不得不放弃了对新测试内容的补充。这显然算不上明智的决定,但在当时的情况下,我 们不得不弃车保帅。经过讨论,我们认为单元测试在避免关键性故障方面的效果并不理想,例如在生产负荷下与多种组件相关的系统问题以及前端渲染问题等。 单元测试是我们的骄傲,在之后的几年中它一直努力工作并帮我们解决了很多大麻烦。而Selenium测试则没那么好运,它几乎在我们停止维护的同时就瞬间失灵了,而且随品质保障团队的离去一道彻底告别了我们。 2. 我们利用Thrift来定义并区分前端及平台团队的专属接口,这些接口的作用是为不同团队之间的沟通与协作提供桥梁。当然我们也果断舍弃了很多存在设计 缺陷的接口,它们都或多或少给工作造成过负面影响。不过总体而言,利用Thrift来定义团队之间的类型与接口非常明智,它为我们提供了非常实用的沟通渠 道。 3. 我们很少会对现有Thrift接口进行改动,一般更倾向于针对需要的功能推出新接口、更新客户端使功能奏效然后删除旧接口。这种处理方式有点尴尬,但是 由于我们是以独立方式分别部署前端及后端代码的(而且会花几分钟时间把全部前端或后端服务器跑一遍),因此这是最安全也最理智的方式。毕竟随意改动会带来 不可知的后果,我们可不想让多年的心血毁在自己鲁莽的尝试中。 4. 我们利用一种新机制来启动所有前端变更,并将其带入用户的子集中或者在出现问题时加以禁用。这种方式令我们将部署与试运行分离开来,进而保证了代码部署工作的安全性与稳定性,同时也赋予了我们准时完成新功能开发的能力。 起初我们打算利用这种机制对新功能进行A/B测试,但后来我们发现它最大的价值在于管理发行版以及收集来自受信任用户群组的反馈意见。 我们还启用了一些后端功能,希望借此解决极端情况下的性能或负载冲击。万事想在前头才好,否则出现问题时我们只能盯着Jenkins的进度条手足无措了。 聊完了过去的开发历程,我们再来看看开发出的系统成品。 康威如是说,或者叫“架构” 如果大家看了我们在设计v4架构时所采用的组织结构,再看看我们开发出的架构,就会发现这基本上就是康威定律的现实版体现。 我们拥有一个API团队和一台API服务器、一个前端团队和一台前端服务器、一个平台团队和一台后端服务器、一个广告团队和一台广告服务器、一大堆由基础设施团队管理着的存储数据以及专为分析团队准备的Hadoop集群。
也就是说,对我们的团队规模而言,这是一套非常标准的组织结构。其中前端团队负责通过PHP/HTML/JS进行统一开发,状态及存储则由后端服务器管理,同时消息队列则处理长时间运行的项目以及非事务类流程。 最特别的方面当数后端服务器了,这些Thrift服务器以gevent为基础。但遗憾的是我们连一台标准的高性能Python Thrift服务器也没有,所以花了大量时间与gevent打交道,并想尽办法让gevent能安全地服务于客户端池。另外我们还尽量避免在Python 服务器上使用Thrift,这么做主要是为了减少同类服务器的使用量。 同时管理PHP及Python服务器的感觉令人抓狂,我的心中一直回响着“我从来没想到会遇到这种情况”的声音。但实践出真知,我发现实际操作中并 没出现过太大的问题:在过去的一年时间里,我们团队中的几乎每位成员都以轻松愉快的心情同时使用这两种语言,我也没听到过什么抱怨之声。 作为力求系统产品完美的设计人员,使用Tornado、Apache+modwsgi+Pylons以及Python gevent服务器的现状令我心生愤懑,不过跟上面几个问题一样,实际操作中没遇到过什么障碍(但这要归功于Jenkins与Puppet在系统部署方面 的帮助,没有它们俩相信整个流程会变得更加枯燥而痛苦)。 结束语 总而言之,我认为我们的流程及架构非常合理,而且也很适合我们的工作习惯。如果我们的项目今天才刚刚开始,那么采用的方案很可能完全不同;如果我们 的团队没有经历严重人员流失、如果我们没有因为资金不足而不得不同时管理多套遗留系统与API……无数个如果会带来无数个故事,这些有趣的话题不妨今后慢 慢聊。 在为Digg付出了无数个日夜的辛勤劳作后,我认为围绕数据库与技术增值话题同样值得写一篇专题(包括Cassandra, MySQL, Redis, Memcache, HDFS, Hive, Hadoop, Tornado, Thrift servers, PHP, Python, Pylons, Gevent等等),但现在我还需要积蓄一些灵感。 转载请保留固定链接: https://linuxeye.com/architecture/766.html |