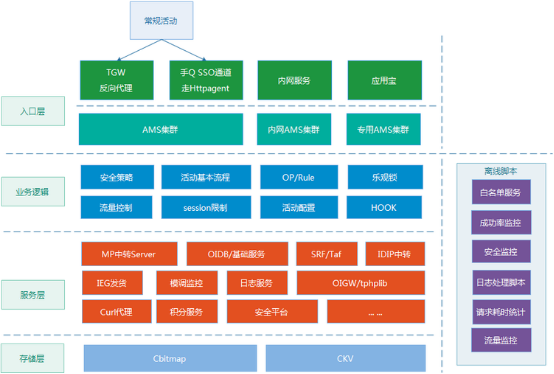
三 年多前,我在腾讯负责的活动运营系统,因为业务流量规模的数倍增长,系统出现了各种各样的异常,那个时候,我7*24小时地没日没夜处理告警,周末和凌晨 也经常上线,疲于奔命。后来,当时的老领导对我说:你不能总扮演一个“救火队长”的角色, 要尝试从系统整体层面思考产生问题的根本原因,然后推进解决。 我幡然醒悟,“火”是永远救不完的,让系统能够自动”灭火”,才是解决问题的正确方向。简而言之,系统的异常不能总是依赖于“人”去恢复,让系统本身具备 “容错”能力,才是根本解决之道。三年多过去了,我仍然负责着这个系统,而它也已经从一个日请求百万级的小Web系统,逐步成长为一个高峰日请求达到8亿 规模的平台级系统,走过一段令人难忘的技术历程。 容错其实是系统健壮性的重要指标之一,而本文会主要聚焦于“容错”能力的实践,希望对做技术的同学有所启发和帮助。 (备注:QQ会员活动运营平台,后面统一简称AMS)
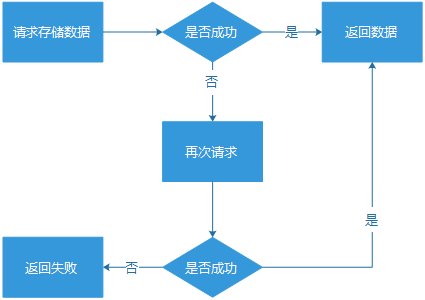
一、 重试机制 最容易也最简单被人想到的容错方式,当然就是“失败重试”,总而言之,简单粗暴!简单是指它的实现通常很简单,粗暴则是指使用不当,很可能会带来系统“雪崩”的风险,因为重试意味着对后端服务的双倍请求。
1. 简单重试 我 们请求一个服务,如果服务请求失败,则重试一次。假设,这个服务在常规状态下是99.9%的成功率,因为某一次波动性的异常,成功率下跌到95%,那么如 果有重试机制,那么成功率大概还能保持在99.75%。而简单重试的缺陷也很明显,如果服务真的出问题,很可能带来双倍流量,冲击服务系统,有可能直接将 服务冲垮。而在实际的真实业务场景,往往更严重,一个功能不可用,往往更容易引起用户的“反复点击”,反而制造更大规模的流量冲击。比起服务的成功率比较 低,系统直接被冲击到“挂掉”的后果明显更严重。
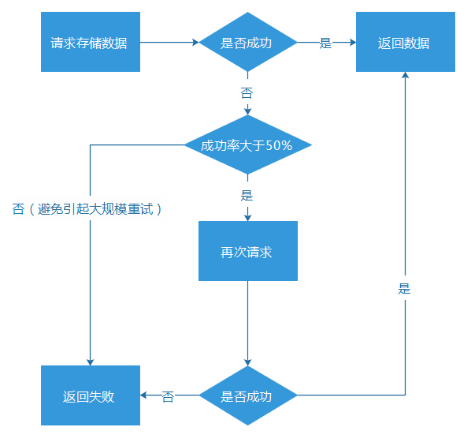
简单重试,要使用在恰当的场景。或者,主动计算服务成功率,成功率过低,就直接不做重试行为,避免带来过高的流量冲击。
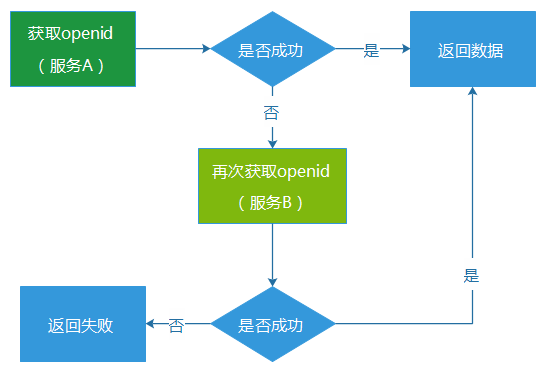
2. 主备服务自动切换 既 然单一服务的重试,可能会给该带来双倍的流量冲击,而最终导致更严重的后果,那么我们不如将场景变为主备服务的自动重试或者切换。例如,我们搭建了两套获 取openid的服务,如果服务A获取失败,则尝试从服务B中获取。因为重试的请求压力是压到了服务B上,服务A通常不会因为重试而产生双倍的流量冲击。
这种重试的机制,看似比较可用,而实际上也存在一些问题: (1) 通 常会存在“资源浪费”的问题。因为备份服务系统,很可能长期处于闲置状态,只有在主服务异常的时候,它的资源才会被比较充分地使用。不过,如果对于核心的 服务业务(例如核心数据、营收相关)进行类似的部署,虽然会增加一些机器成本和预算,但这个付出通常也是物有所值的。 (2) 触 发重试机制,对于用户的请求来说,耗时必然增加。主服务请求失败,然后再到备份服务请求,这个环节的请求耗时就至少翻倍增长,假设主服务出现连接 (connect)超时,那么耗时就更是大幅度增加。一个服务在正常状态下,获取数据也许只要50ms,而服务的超时时间通常会设置到 500-1000ms,甚至更多,一旦出现超时重试的场景,请求耗时必然大幅度增长,很可能会比较严重地影响用户体验。 (3) 主备服务一起陷入异常。如果是因为流量过大问题导致主服务异常,那么备份服务很可能也会承受不住这种级别的流量而挂掉。 重试的容错机制,在AMS上有使用,但是相对比较少,因为我们认为主备服务,还是不足够可靠。
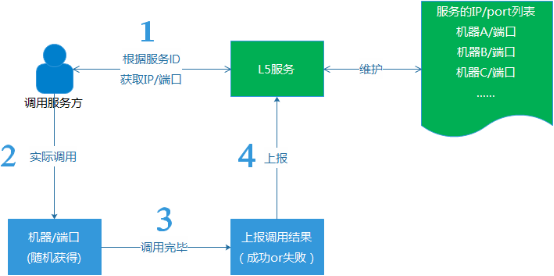
二、 动态剔除或者恢复异常机器 在AMS里,我们的后端涉及数以百计的各类服务,来支撑整个运营系统的正常运作。所有后端服务或者存储,首先是部署为无状态的方式提供服务(一个服务通常很多台机器),然后,通过公司内的一个公共的智能路由服务L5,纳入到AMS中。 (1) 所 有服务与存储,无状态路由。这样做的目的,主要是为了避免单点风险,就是避免某个服务节点挂了,导致整个服务就瘫痪了。实际上,即使像一些具有主备性质 (主机器挂了,支持切换到备份机器)的接入服务,也是不够可靠的,毕竟只有2台,它们都挂了的情况,还是可能发生的。我们后端的服务,通常都以一组机器的 形式提供服务,彼此之间没有状态关系,支撑随机分配请求。 (2) 支持平行扩容。遇到大流量场景,支持加机器扩容。 (3) 自动剔除异常机器。在我们的路由服务,发现某个服务的机器异常的时候(成功率低于50%),就会自动剔除该机器,后续,会发出试探性的请求,确认等它恢复正常之后,再重新加回到服务机器组。
例 如,假如一组服务下拥有服务机器四台(ABCD),假设A机器的服务因为某种未知原因,完全不可用了,这个时候L5服务会主动将A机器自动从服务组里剔 除,只保留BCD三台机器对外提供服务。而在后续,假如A机器从异常中恢复了,那么L5再主动将机器A加回来,最后,又变成ABCD四台机器对外提供服 务。 在过去的3年里,我们逐步将AMS内的服务,渐渐从写死IP列 表或者主备状态的服务,全部升级和优化为L5模式的服务,慢慢实现了AMS后端服务的自我容错能力。至少,我们已经比较少遇到,再因为某一台机器的软件或 者硬件故障,而不得不人工介入处理的情况。我们也慢慢地从疲于奔命地处理告警的苦难中,被解放出来。
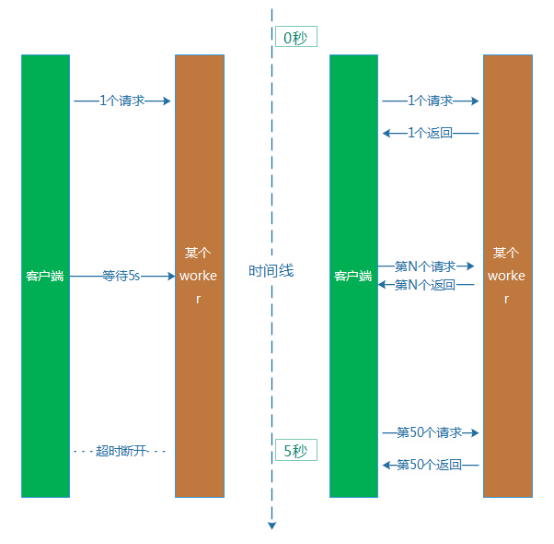
三、 超时时间 1. 为服务和存储设置合理的超时时间 调用任何一个服务或者存储,一个合理的超时时间(超时时间,就是我们请求一个服务时,等待的最长时间),是非常重要的,而这一点往往比较容易被忽视。通常Web系统和后端服务的通信方式,是同步等待的模式。这种模式,它会带来的问题比较多。 对 于服务端,影响比较大的一个问题,就是它会严重影响系统吞吐率。假设,我们一个服务的机器上,启用了100个处理请求的worker,worker的超时 时间设置为5秒,1个worker处理1个任务的平均处理耗时是100ms。那么1个work在5秒钟的时间里,能够处理50个用户请求,然而,一旦网络 或者服务偶尔异常,响应超时,那么在本次处理的后续整整5秒里,它仅仅处理了1个等待超时的失败任务。一旦比较大概率出现这类型的超时异常,系统的吞吐率 就会大面积下降,有可能耗尽所有的worker(资源被占据,全部在等待状态,知道5s超时才释放),最终导致新的请求无worker可用,只能陷入异常 状态。
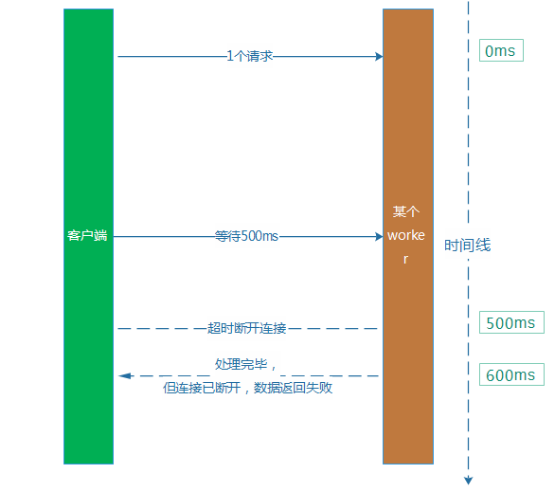
算上网络通信和其他环节的耗时,用户就等待了超过5s时间,最后却获得一个异常的结果,用户的心情通常是崩溃的。 解 决这个问题的方式,就是设置一个合理的超时时间。例如,回到上面的的例子,平均处理耗时是100ms,那么我们不如将超时时间从5s下调到500ms。从 直观上看,它就解决了吞吐率下降和用户等待过长的问题。然而,这样做本身又比较容易带来新的问题,就是会引起服务的成功率下降。因为平均耗时是 100ms,但是,部分业务请求本身耗时比较长,耗时超过500ms也比较多。例如,某个请求服务端耗时600ms才处理完毕,然后这个时候,客户端认为 等待超过500ms,已经断开了连接。处理耗时比较长的这类型业务请求会受到比较明显的影响。
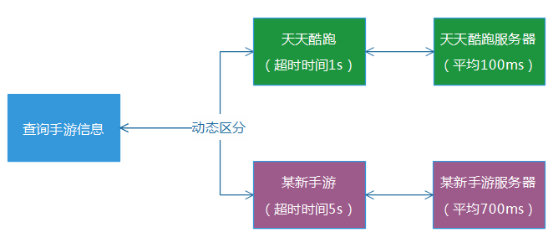
2. 超时时间设置过短带来的成功率下降 超时时间设置过短,会将很多本来处理成功的请求,当做服务超时处理掉,进而引起服务成功率下降。将全部业务服务,以一刀切的方式设置一个超时时间,是比较不可取的。优化的方法,我们分为两个方向。 (1) 快慢分离 根 据实际的业务维度,区分对待地给各个业务服务配置不同的超时时间,同时,最好也将它们的部署服务也分离出来。例如,天天酷跑的查询服务耗时通常为 100ms,那么超时时间我们就设置为1s,某新手游的查询服务通常耗时为700ms,那么我们就设置为5s。这样的话,整体系统的成功率,就不会受到比 较大的影响。
(2) 解决同步阻塞等待 “快慢分离”可以改善系统的同步等待问题,但是,对于某些耗时本来就比较长的服务而言,系统的进程/线程资源仍然在同步等待过程中,无法响应其他新的请求,只能阻塞等待,它的资源仍然是被占据,系统的整体吞吐率仍然被大幅度拉低。 解 决的思路,当然是利用I/O多路复用,通过异步回调的方式,解决同步等待过程中的资源浪费。AMS的一些核心服务,采用的就是“协程”(又叫“微线程”, 简单的说,常规异步程序代码里嵌套比较多层的函数回调,编写复杂。而协程则提供了一种类似写同步代码的方式,来写异步回调程序),以解决同步等待的问题。 异步处理的简单描述,就是当进程遇到I/O网络阻塞时,就保留现场,立刻切换去处理下一个业务请求,进程不会因为某个网络等待而停止处理业务,进而,系统 吞吐率即使遇到网络等待时间过长的场景,通常都能保持在比较高的水平。 值得补充一点的是,异步处理只是解决系统的吞吐率问题,对于用户的体验问题,并不会有改善,用户需要等待的时间并不会减少。
3. 防重入,防止重复发货 前面我们提到,我们设置了一个比较“合理的超时时间”,简而言之,就是一个比较短的超时时间。而在数据写入的场景,会引起新的问题,就我们的AMS系统而言,就是发货场景。如果是发货请求超时,这个时候,我们需要思考的问题就比较多了。
(1) 发货等待超时,发货服务执行发货失败。这种场景,问题不大,后续用户重新点击领取按钮,就可以触发下一次重新发货。 (2) 发货等待超时,发货服务实际在更晚的时候执行发货成功,我们称之为“超时成功”。最可怕的场景,则是每次都是发货超时,而实际上都发货成功,有可能导致用户可以无限领取礼包,最终造成活动运营事故。
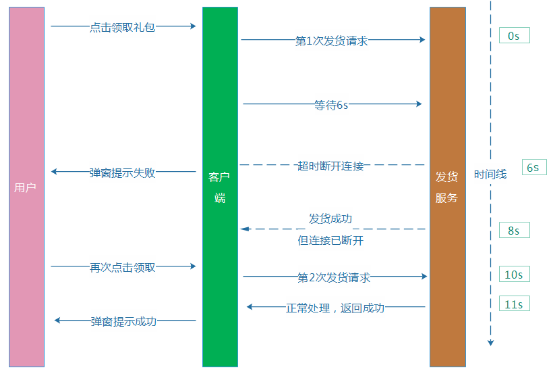
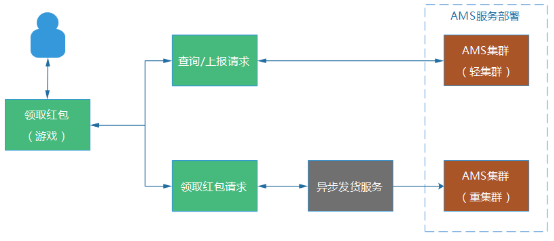
第二种场景,给我们带来了比较麻烦的问题,如果处理不当,用户再次点击,就触发第多次“额外”发货。 例 如,我们假设某个发货服务超时时间设置为6s,用户点击按钮,我们的AMS收到请求后,请求发货服务发货,等待6s后,无响应,我们给用户提示“领取失 败”,而实际上发货服务却在第8秒执行发货成功,礼包到了用户的账户上。而用户看见“领取失败”,则又再次点击按钮,最终导致“额外”多发一个礼包给到这 个用户。 例子的时序和流程图大致如下:
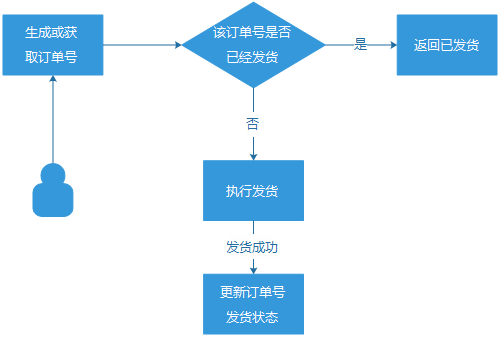
这 里就提到了防重入,简单的说,就是如何确认不管用户点击多少次这个领取按钮,我们都确保结果只有一种预期结果,就是只会给用户发一次礼包,而不引起重复发 货。我们的AMS活动运营平台一年上线的活动超过4000个,涉及数以万计的各种类型、不同业务系统的礼包发货,业务通信场景比较复杂。针对不同的业务场 景,我们做了不同的解决方案: (1) 业务层面限制,设置礼包单用户限量。在发货服务器的源头,设置好一个用户仅能最多获得1个礼包,直接避免重复发放。但是,这种业务限制,并非每个业务场景都通用的,只限于内部具备该限制能力的业务发货系统,并且,有一些礼包本身就可以多次领取的,就不适用了。 (2) 订 单号机制。用户的每一次符合资格的发货请求,都生成一个订单号与之对应,通过它来确保1个订单号,只发货1次。这个方案虽然比较完善,但是,它是依赖于发 货服务方配合做“订单号发货状态更新“的,而我们的发货业务方众多,并非每一个都能支持”订单号更新“的场景。
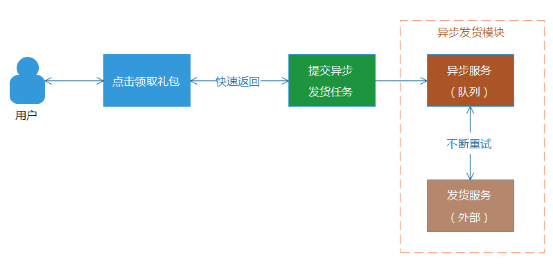
(3) 自 动重试的异步发货模式。用户点击领取礼包按钮后,Web端直接返回成功,并且提示礼包在30分钟内到账。对于后台,则将该发货录入到发货队列或者存储中, 等待发货服务异步发货。因为是异步处理,可以多次执行发货重试操作,直到发货成功为止。同时,异步发货是可以设置一个比较长的超时等待时间,通常不会出现 “超时成功”的场景,并且对于前端响应来说,不需要等待后台发货状态的返回。但是,这种模式,会给用户带来比较不好的体验,就是没有实时反馈,无法立刻告 诉用户,礼包是否到账。
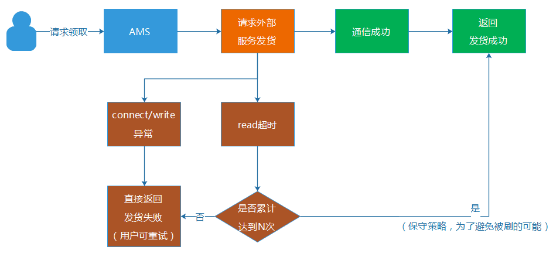
4. 非订单号的特殊防刷机制 某 些特殊的合作场景,我们无法使用双方约定订单号方式,例如一个完全隔离独立的外部发货接口,不能和我们做订单号的约定。基于这种场景,我们AMS专门做了 一种防刷的机制,就是通过限制read超时的次数。但是,这种方案并非完美解决重复发货问题,只是能起到够尽可能减少避免被刷的作用。一次网络通信,通常 包含:建立连接(connect),写入数据发包(write),等待并且读取回包(read),断开连接(close)。
通 常一个发货服务如果出现异常,大多数情况,在connect步骤就是失败或者超时,而如果一个请求走到等待回包(read)时超时,那么发货服务另外一边 就有可能发生了“超时但发货成功”的场景。这个时候,我们将read超时的发生次数记录起来,然后提供了一个配置限制次数的能力。假如设置为2次,那么当 一个用户第一次领取礼包,遇到read超时,我们就允许它重试,当还遇到第二次read超时,就达到我们之前设置的阀值2,我们就认为它可能发货成功,拒 绝用户的第三次领取请求。
这种做法,假设发货服务真的出现很多超时成功,那么用户也最多只能刷到2次礼包(次数可配置),而避免发生礼包无限制被刷的场景。但是,这种方案并不完全可靠,谨慎使用。
四、 服务降级,自动屏蔽非核心分支异常 对 于一次礼包领取请求,在我们的后端CGI会经过10多个环节和服务的逻辑判断,包括礼包配置读取、礼包限量检查、登陆态校验、安全保护等等。而这些服务 中,就有不可以跳过的核心环节,例如读取礼包配置的服务,也有非核心环节,例如数据上报。对于非核心环节,我们的做法,就是设置一个比较低的超时时间。 例如我们其中一个统计上报服务,平均耗时是3ms,那么我们就将超时时间设置为20ms,一旦超时则旁路掉,继续按照正常逻辑走业务流程。
五、 服务解耦、物理隔离 虽 然,大家都知道一个服务的设计,要尽可能小和分离部署,如此,服务之间的耦合会比较小,一旦某个模块出问题,受到影响的模块就比较少,容错能力就会更强。 可是,从设计之初,就将每一个服务有序的切割地很小,这个需要设计者具备超前的意识,能够提前意识到业务和系统的发展形态,而实际上,业务的发展往往是比 较难以预知的,因为业务的形态会随着产品的策略的改变而变化。在业务早期流量比较小的时候,通常也没有足够的人力和资源,将服务细细的切分。AMS从日请 求百万级的Web系统,逐渐成长为亿级,在这个过程中,流量规模增长了100倍,我们经历了不少服务耦合带来的阵痛。
1. 服务分离,大服务变成多个小服务 我 们常常说,鸡蛋不能都放在一个篮子里。AMS以前是一个比较小的系统(日请求百万级,在腾讯公司内完全是一个不起眼的小Web系统),因此,很多服务和存 储在早起都是部署在一起的,查询和发货服务都放在一起,不管哪一个出问题,都相互影响。后来,我们逐渐的将这些核心的服务和存储,慢慢地分离出来,细细切 分和重新部署。在数据存储方面,我们将原来3-5个存储的服务,慢慢地切为20多个独立部署的存储。 例如,2015年下半年,我们就将其中一个核心的存储数据,从1个分离为3个。
这样做带来了很多好处: (1) 原来主存储的压力被分流。 (2) 稳定性更高,不再是其中一个出问题,影响整个大的模块。 (3) 存储之间是彼此物理隔离的,即使服务器硬件故障,也不会相互影响。
2. 轻重分离,物理隔离 另 外一方面,我们对于一些核心的业务,进行“轻重分离”。例如,我们支持2016年“手Q春节红包”活动项目的服务集群。就将负责信息查询和红包礼包发货的 集群分别独立部署,信息查询的服务相对没有那么重要,业务流程比较轻量级,而红包礼包发货则属于非常核心的业务,业务流程比较重。
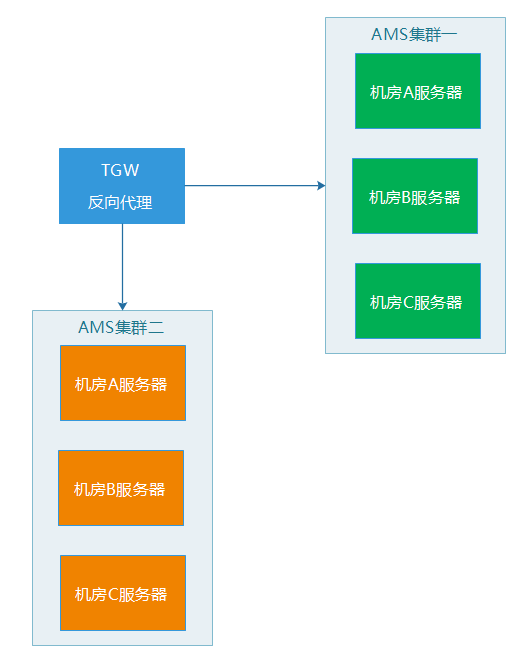
轻重分离的这个部署方式,可以给我们带来一些好处: (1) 查询集群即使出问题,也不会影响发货集群,保证用户核心功能正常。 (2) 两边的机器和部署的服务基本一致,在紧急的情况下,两边的集群可以相互支援和切换,起到容灾的效果。 (3) 每个集群里的机器,都是跨机房部署,例如,服务器都是分布在ABC三个机房,假设B机房整个网络故障了,反向代理服务会将无法接受服务的B机房机器剔除,然后,剩下AC机房的服务器仍然可以正常为外界提供服务。
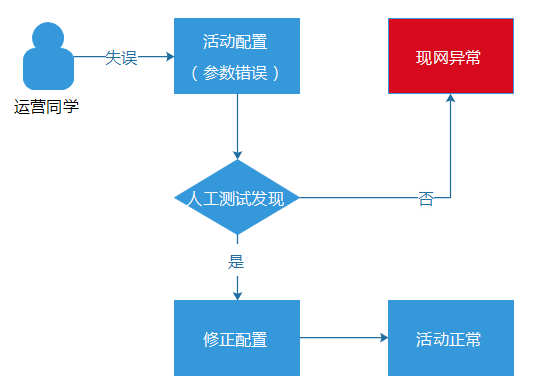
六、 业务层面的容错 如 果系统架构设计层面的“容错”我们都搭建完善了,那么再继续下一层容错,就需要根据实际的业务来进行,因为,不同的业务拥有不同的业务逻辑特性,也能够导 致业务层面的各种问题。而在业务层面的容错,简而言之,避免“人的失误”。不管一个人做事性格多么谨慎细心,也总有“手抖”的时候,在不经意间产生“失 误”。AMS是一个活动运营平台,一个月会上线400多个活动,涉及数以千计的活动配置信息(包括礼包、规则、活动参与逻辑等等)。在我们的业务场景下, 因为种种原因而导致“人的失误”并不少。 例如,某个运营同学看错礼 包发放的日限量,将原本只允许1天放量100个礼包的资源,错误地配置为每天放量200个。这种错误是测试同学比较难测试出来的,等到活动真正上线,礼包 发放到101个的时候,就报错了,因为资源池当天已经没有资源了。虽然,我们的业务告警系统能够快速捕获到这个异常(每10分钟为一个周期,从十多个维 度,监控和计算各个活动的成功率、流量波动等等数据),但是,对于腾讯的用户量级来说,即使只影响十多分钟,也可以影响成千上万的用户,对于大规模流量的 推广活动,甚至可以影响数十万用户了。这样的话,就很容易就造成严重的“现网事故”。
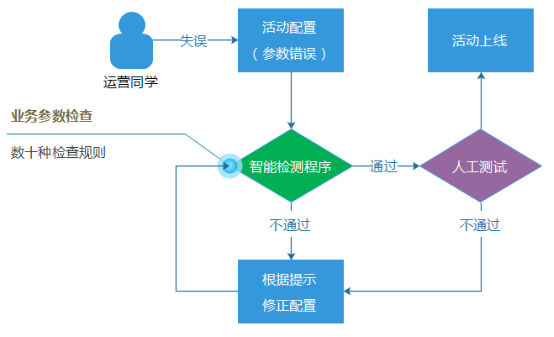
完 善的监控系统能够及时发现问题,防止影响面的进一步扩大和失控,但是,它并不能杜绝现网问题的发生。而真正的根治之法,当然是从起源的地方杜绝这种场景的 出现,回到上面“日限量配置错误”的例子场景中,用户在内部管理端发布活动配置时,就直接提示运营同学,这个配置规则是不对的。 在业界,因为配置参数错误而导致的现网重大事故的例子,可以说是多不胜数,“配置参数问题”几乎可以说是一个业界难题,对于解决或者缓解这种错误的发生,并没有放之四海而皆准的方法,更多的是需要根据具体业务和系统场景,亦步亦趋地逐步建设配套的检查机制程序或者脚本。 因此,我们建设了一套强大并且智能的配置检查系统,里面集合了数十种业务的搭配检查规则,并且检查规则的数目一直都在增加。这里规则包括检查礼包日限量之类比较简单的规则,也有检查各种关联配置参数、相对比较复杂的业务逻辑规则。
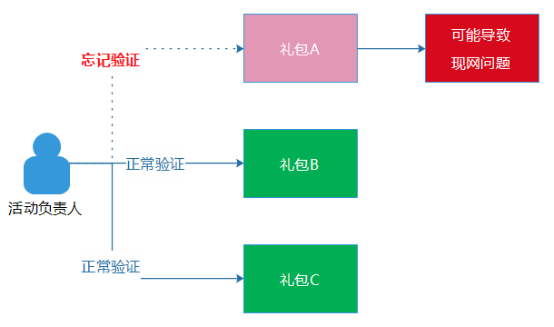
另 外一方面,流程的执行不能通过“口头约定”,也应该固化为平台程序的一部分,例如,活动上线之前,我们要求负责活动的同事需要验证一下“礼包领取逻辑”, 也就是真实的去领取一次礼包。然而,这只是一个“口头约定”,实际上并不具备强制执行力,如果这位同事因为活动的礼包过多,而漏过其中一个礼包的验证流 程,这种事情也的确偶尔会发生,这个也算是“人的失误”的另外一种场景。
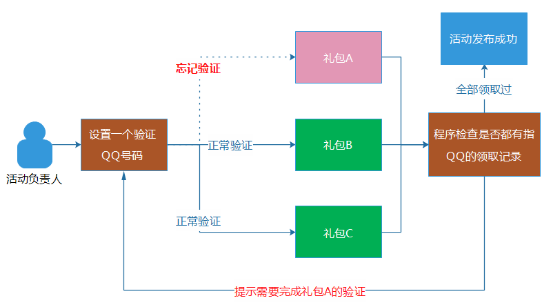
为 了解决问题,这个流程在我们AMS的内部管理端中,是通过程序去保证的,确保这位同事的QQ号码的确领取过全部的礼包。做法其实挺简单的,就是让负责活动 的同事设置一个验证活动的QQ号码,然后,程序在发货活动时,程序会自动检查每一个子活动项目中,是否有这个QQ号码的活动参与记录。如果都有参与记录, 则说明这位同事完整地领取了全部礼包。同时,其他模块的验证和测试,我们也都采用程序和平台来保证,而不是通过“口头约定”。
通过程序和系统对业务逻辑和流程的保证,尽可能防止“人的失误”。 这种业务配置检查程序,除了可以减少问题的发生,实际上也减轻了测试和验证活动的工作,可以起到节省人力的效果。不过,业务配置检查规则的建设并不简单,逻辑往往比较复杂,因为要防止误杀。
七、 小结 无 论是人还是机器,都是会产生“失误”,只是对于单一个体,发生的概率通常并不大。但是,如果一个系统拥有数百台服务器,或者有一项工作有几百人共同参与, 这种“失误“的概率就被大大提升,失误很可能就变为一种常态了。机器的故障,尽可能让系统本身去兼容和恢复,人的失误,尽可能通过程序和系统流程来避免, 都尽可能做到”不依赖于人“。
容错的核心价值,除了增强系统的健壮性外,我觉得是解放技术人员,尽可能让我们不用凌晨起来处理告警,或享受一个相对平凡闲暇的周末。对于我们来说,要完全做到这点,还有很长的路要走,与君共勉。 转载请保留固定链接: https://linuxeye.com/architecture/2884.html |