定义:
首先,我们定义一下定向抓取,定向抓取是一种特定的抓取需求,目标站点是已知的,站点的页面是已知的。本文的介绍里面,主要是侧重于如何快速构建一个实时的抓取系统,并不包含通用意义上的比如链接分析,站点发现等等特性。
在本文提到的实例系统里面,主要用到 linux+mysql+redis+django+scrapy+webkit,其中scrapy+webkit作为抓取端,redis作为链接库存 储,mysql作为网页信息存储,django作为爬虫管理界面,快速实现分布式抓取系统的原型。
名词解析:
1. 抓取环:抓取环指的是spider在存储中获取url,从互联网上下载网页,然后将网页存储到数据库里面,最后在从存储里面获取下一个URL的一个流程。
2. Linkbase:链接库的存储模块,包含一般的链接信息;是抓取系统的核心,使用redis存储。 3. XPATH:一门在 XML 文档中查找信息的语言,XPath 可用来在 XML 文档中对元素和属性进行遍历, 是 W3C XSLT 标准的主要元素。使用XPATH以及相关工具lib进行链接抽取和信息抽取。 4. XPathOnClick:一个chrome的插件,支持点击页面元素,获取XPATH路径,用于编辑配置模板。 5. Redis:一个开源的KV的内存数据库,具备很好的数据结构的特征和很高的存取性能。用于存储linkbase信息 6. Django:爬虫管理工具,用于模板配置,系统监控反馈。Django在这里主要是用来管理一个数据库,使用Admin功能。 7. Pagebase:页面库,主要是存储网页抓取的结果,以及页面抽取的结果,和dump交互,使用mysql实现。 8. Scrapy:一个开源的机遇twisted框架的python的单机爬虫,该爬虫实际上包含大多数网页抓取的工具包,用于爬虫下载端以及抽取端。 9. 列表页:指的商品页面之外的所有页面 10. 详情页:比如商品B2C的抓取中,特指商品页面,比如:http://item.tmall.com/item.htm?id=10321272374
系统架构
一:存储 redis+mysql
链接库(linkbase)是抓取系统的核心,基于性能和效率的考虑,本文采用基于内存的redis和磁盘的mysql为主,对于linkbase主要是 存储抓取必须的链接信息,比如url,anchor,等等;对于mysql,则是存放抓取的网页,便于后续的抽取和处理。
a) PageBase:使用Mysql分库分表,存放网页,如下图:
 b) Linkbase 使用Redis集群,存储linkbase信息。 
几个基本的数据结构:
1:抓取队列 (candidate list) 分为待抓取的url队列和更新的url队列;队列存放urlhash,使用redis的list数据结构,对于新提取的url,push到对应的列表里 面,对于spider抓取模块,从list pop得到。对于一个站点而言,抓取队列有两种类型:列表页抓取队列和详情页抓取队列。 2:链接库 (linkbase) 链接库实际上是存储链接信息的DB;Key是urlhash,Value是linkinfo,包含url,purl,anchor,xpath。。。;在redis使用hash存储,直接存放在redis的里面。KV链接库,不区分页面类型。 3:已抓取集合(crawled_set) 已抓取集合指的是当前已经下载的页面的urlhash,存放已经抓取的网页,使用redis的set实现,set的key是urlhash,score是 时间戳,已抓取集合主要是用来记录哪一些页面已经抓取和抓取的时间,用于后续的更新页面调度以及抓取信息的统计。同抓取队列一样,每一个站点有两种类型的 已抓取集合,详情页和列表页
二:调度模块:
调度模块是抓取系统的关键,调度系统的好坏决定了抓取系统的效率;这块是主要是在redis linkbase之上的数据结构,主要有抓取队列、抓取集合、抓取优先级等等数据结构组成;对于一个抓取循环来说:获取URL,提交到抓取模块的待抓取队 列,启动抓取,抓取完成之后对新链接进行抽取,最后进入等待抓取的队列里面。
调度系统的基本配置:
a) 频率(间隔多少秒) b) 各个抓取列表的选取比例:get_detail,mod_detail,get_list,mod_list 链接抽取:抽取页面的链接,进行除重,对于新的链接,插入到待抓取列表里 内容抽取:按照模块的配置XPATH,抽取页面信息,并写入到pagebase中。 离线调度:按照更新的比例,从crawled_set里面,定期选取url进入Mod队列里面进行刷新。
三:抓取模块:
抓取模块是抓取的必要条件,抓取模块来说,重要的是应付互联网上各式的问题,以及如何实现对对方站点的ip平衡,当然,这块是和调度系统的紧密结合的,对于抓取模块而言,本文主要使用scrapy工具包里面的下载模块。
首先,抓取模块从linkbase获取对应站点的抓取url,进行页面下载,然后将页面信息写回到pipeline中,并完成链接抽取和页面抽取,同时调用调度模块,插入到linkbase和pagebase中。
下载端设计: IP:每台机器需要配置多个物理公网IP,下载的时候,随机选择一个IP下载 抓取频度调整:读取配置文件,按照配置文件的抓取频率进行选取url
四:配置界面:
配置界面主要是对抓取系统的管理和配置,包括:站点feed、页面模块抽取、报表系统的反馈等等。
类似于通用的抓取架构,本文提到的抓取系统架构如下图:
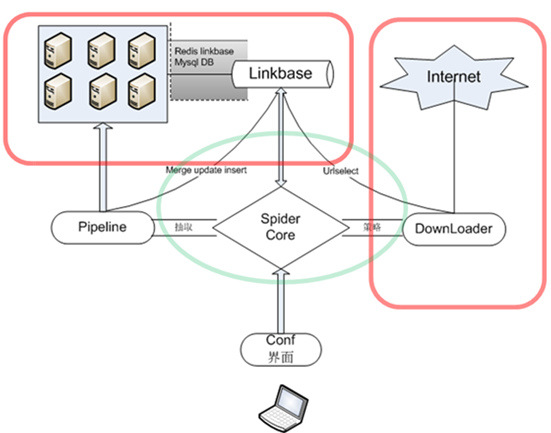
一个完整的抓取数据流:
1:用户提供种子URL
2:种子URL进入linkbase中新URL队列中
3:调度模块选取url进入到抓取模块的待抓取队列中
4:抓取模块读取站点的配置文件,按照执行的频率进行抓取
5:抓取的结果返回到pipeline接口中,并完成连接的抽取
6:新发现的连接在linkbase里面进行dedup,并push到linkbase的新URL模块里面
7:调度模块选取url进入抓取模块的待抓取队列,goto 4
8:end
系统扩展
本文提到的抓取系统,核心是调度和存储模块;其中,抓取,存储,调度都是 通过数据进行交互的,因此,模块之间可以任意平行扩展,对于系统规模来说,只需要平行扩展mysql和redis存储服务集群以及抓取集群即可。当然,简 单的扩展会带来一些问题:比如垃圾列表页的泛滥,链接库的膨胀等等问题,这些问题后续在讨论吧。
转载请保留固定链接: https://linuxeye.com/architecture/1485.html |