软件国际化 软件国际化(I18N)是指开发不经过系统性的改变,就能直接支持指定的多个地区文化的软件的软件开发过程。软件国际化对编码和设计都要求严格,代码和设计都必须考虑到各种国家和地区文化差别,软件国际化的目标是开发的软件能适合所有指定人群的使用。由于软件开发者常常会做一些他们自己地区习惯的假设,而这些假设都可能导致发布的软件不能对某一地区文化正确支持,成功的软件国际化开发过程关键在于在设计和编码阶段都需要避免所有文化相关的假设,将程序的执行代码和UI相关的元素分开。 国际化过程中需要关注的包括以下几个方面: 时间和日期的表示 时间的表示由很多因素决定的,这些因素包括年和月的长短,一星期中的哪一天是一个星期的开始,时区差别,是否实施夏令时等等。举例来说,某一时刻在中国北京(GMT+8)的时间表示是 2005年10月10日 星期一 15时54分,这个时刻在伦敦(GMT+0)的时间则应该是October 10, 2005 8:54 AM,对于这个结果,首先注意到的是两地表示时间的方式完全不一样,我们不能期望英国的用户能够看懂中文表示的时间,或者中国的用户都能接受英语形式的时间表示,可见地区文化的差异造成了时间在表现方式上的区别。同时,我们注意到除了时间的表现方式,两地时间还存在七个小时的偏差,这是因为时区造成了两地八小时的偏差,加上伦敦采用夏令时制度,使得两地实际时间偏差就变成了8-1=7小时。 时间和日期的表示中这些问题的存在,使得软件国际化过程中要求不仅仅关注时间值的表现形式,还需要关注如日历制度,夏令时,时区等能造成时间值差别的因素。 数字的表示 数字的表示方式并不是唯一的,不同国家和地区数字表示方式也存在着区别,因此在软件国际化过程中,不能假设本地的数字表现方式也是其他地区用户可以认可的。影响数字表现的因素包括数字字符的表示、数字符号的表示、数字的类型等。举例来说数字一千二百三十四点五七(1234.57)在英语中的表示是1,234.57,而在德语中的表示为1.234,57,印度语中表示如清单1,从这个例子中可以看到不同语言中不仅仅存在单个数字的表示方式区别(如印度语种数字和和其他语言数字有明显区别),小数点和千位分隔符等数字符号表示也存在着巨大的区别。 国际化中,软件内的数字必须根据国家和地区语言和文化上的区别,数字类型(如货币,百分率等)的区别,进行恰当的转换。 清单1 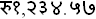 货币的表示 应用程序中会出现货币相关的操作,货币表示非常重要,是国际化开发中不能被忽视的问题。影响货币表示的因素包括:汇率,货币数值小数的表示,货币使用的符号,货币符号的位置等。一个简单的例子来说明货币表示中存在的问题,在今年3月时候, 1美元可以兑换131.17日元,但是用户永远也不可能兑换到131.17日元,这是因为日元中最小的面额就是1日元,日元 (JPY) 通常是不带任何小数位显示的。从这个例子中可以看到,货币兑换过程中有兑换汇率的影响,转换到目标货币下的货币数值需要根据货币实际情况转换表现形式。 国际化中需要考虑影响货币数值表现的各个因素,根据依据目标群体的货币政策和国家文化,恰当地表现货币数值。 度量单位 度量单位直接关系到数值的实际表示结果,虽然,度量单位存在着国际标准,但由于历史,风俗习惯等原因,很多地区及国家并不唯一使用国际标准,因此,度量单位也是国际化中需要考虑的问题。例如说,美国同时存在着国际通用标准制和英制两种度量制度,英制是相对更常用的度量制度,英制中的长度可以使用英寸 (inch)来表示,而国际通用标准是米和分米等; 对于重量的表示,英制使用磅(pound), 而国际标准是克与千克。软件国际化中,当存在度量习惯区别时,软件中度量相关的数据都需要根据度量单位进行合适的转换。 字符排序 即使不同的语言具有相同的字母表都可能具有不同的字母排序顺序,字母字符的排序在各个地区都有个约定成俗的标准。并不是所有语言都把某一个字母的大小写形式看成是等价的,重音的区别,某个符号出现与否,甚至拼写不一致性 都可能导致看似等价的两个字符串实际上的不等价。字符的排序是需要根据不同地域文化确定的。 字符编码集区别 软件中表示文字或者语言中的符号的方式是赋予每一个文字和符号一个独一无二数字值,这样的一个从字符和符号到数字的映射集合便被称为字符编码集。 由于历史的原因,字符集的开发开始都是独立的,导致的结果是,不同国家和地区都可能具有不同的字符集,各种字符编码集也可能是不相兼容的。字符集的差别影响到包括文本的输入、输出格式、存储及排序等涉及到字符操作的多个部分。软件国际化的目标是所有字符集相关内容都能得到合适的操作,这就要求软件不仅仅能够支持目标字符集,还要支持不同字符集之间的字符转换。 ASCII(美国信息互换标准代码)是最常见的字符集,它基于罗马字母表的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,是现今最通用的单字节编码系统。而像中文和日文,这两种语言都拥有远远超过256个字符,就必须使用1个或多个字符来表示一个字符,中国台湾使用的是和大陆不同的字符集,称为Big5,同一个汉字对应的编码不同,便造成了中国海峡两岸计算机文档及各种软件交流时候的乱码问题。 Unicode是一种在计算机上使用的字符编码,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode不仅仅提供了对于任何语言的完善的文字支持, 而且提供了一个全面的数学与技术符号集,因此,Unicode作为取代所有其他编码方式的优秀字符集,将成为文字编码的主流,应用在所有具有文字编码的地方。 软件的国际化过程最合适的方法就是使用Unicode作为软件内部文本的字符集,围绕Unicode字符集,进行字符串排序,输出等文本操作。对于国际化应用的开发组件,Unicode的支持必不可少,作为基于Unicode的国际化开发组件,ICU4C通过对Unicode完善的支持给软件提供了强大的国际化能力。 文本的输入和呈现 软件国际化开发时候不能对文本的输入和呈现有任何假设,包括每个字符占多大的空间,文字呈现的方向,或者呈现屏幕从哪里开始;也不要假设按键次数是和字符一对一的。例如,阿拉伯人和希伯来人的阅读习惯是从右向左,文本输入也是从右向左,这样的习惯被称为BIDI(Bidirectionality)。BIDI是国际化中重要内容,使用到BIDI的地方必须额外的注意,BIDI的特点包括: (1) 本土语言(阿拉伯和希伯来语等) 写的方向为从右往左 (2) 数字和非本土语言(如英语,法语) 写的方向为从左往右 (3) 文本呈现方向整体来说是从右往左,例 清单2 清单2, BIDI UI 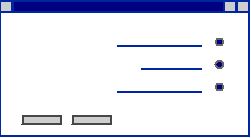 什么是ICU4C ICU4C是ICU在C/C++平台下的版本, ICU(International Component for Unicode)是基于"IBM公共许可证"的,与开源组织合作研究的, 用于支持软件国际化的开源项目。ICU4C提供了C/C++平台强大的国际化开发能力,软件开发者几乎可以使用ICU4C解决任何国际化的问题,根据各地的风俗和语言习惯,实现对数字、货币、时间、日期、和消息的格式化、解析,对字符串进行大小写转换、整理、搜索和排序等功能,必须一提的是,ICU4C提供了强大的BIDI算法,对阿拉伯语等BIDI语言提供了完善的支持。 ICU首先是由Taligent公司开发的,Taligent公司现在被合并为IBM?公司全球化认证中心的Unicode研究组,然后ICU由IBM和开源组织合作继续开发,开源组织给与了ICU极大的帮助。 开始ICU只有Java平台的版本,后来这个平台下的ICU类被吸纳入SUN公司开发的JDK1.1,并在JDK以后的版本中不断改进。C++和C平台下的ICU是由JAVA平台下的ICU移植过来的,移植过的版本被称为ICU4C,来支持这C/C++两个平台下的国际化应用。 ICU4C和ICU4C区别不大,但由于ICU4C是开源的,并且紧密跟进Unicode标准,ICU4C支持的Unicode标准总是最新的;同时,因为JAVA平台的ICU4J的发布需要和JDK绑定,ICU4C支持Unicode标准改变的速度要比ICU4J快的多。 ICU4C的特性 ICU4C有效地增强了C/C++平台的软件国际化能力,它使得开发者可以写出独立于风俗和语言的C/C++代码,然后这些代码可以通过利用相关资源组成语言和风俗相关软件。ICU4C除了具有对Unicode强大的支持能力以外,针对国际化中的各种问题,ICU4C提供了强大的国际化问题解决能力,ICU4C国际化的特性包括: 170+种 Locale支持 虽然Unicode给文本提供了统一的表示方法,但是除了文本表示,各种各样的地域和文化区别仍然存在于不同的系统中。软件国际化推荐的方式是在软件内部使用语言/文化独立的数据,再根据目标平台的语言/文化规则来为目标平台格式化这些数据。 在文章前面的内容中,我们不断提到区域语言,文化和习惯这样一个概念,Locale就是这个概念的概括,它标识了一个特定的用户群体, 这个群体中的用户对于人和计算机交互有着相近的文化和语言。和Locale相关联的数据就是前述的那些目标平台相关的规则,这些规则给日期、数字、货币格式化,度量单位转换,字符串整理(排序),时区转换,边界分析(字符,字符串,句子),文本标准化以及音译等国际化操作提供了支持。 Locale的广泛支持是国际化开发包的重要条件,支持的Locale种类越多,说明开发出来的应用程序适用的范围越广,ICU4C作为C/C++平台强大的国际化开发组件,提供了超过170种Locale的支持。 ICU中的Locale ID和POSIX定义的Locale ID 是不同的,ICU中的Locale ID被认为是轻量级,因为它区别于POSIX的定义,没有指定Locale相关的字符编码,并且细化具有某些区别的类似群体成为不同的Locale。ICU4C中的Locale是由语言(language),可选的语言编码(script),国家(country),可选的变量(variable)和可选的关键字(keyword) 这几个域组成,可选的域可以被用于根据特定区别细化Locale。ICU中的Locale ID组成格式在清单3中: 清单3
locale_id := 基本LocaleID 关键字
基本LocaleID := language_code ("_" script_code)? ("_" _code)? ("_" variant_code)?
关键字:= "@" key "=" type ("," key "=" type )*
用户使用Locale ID 来请求Locale相关的ICU服务。除了Locale相关服务以外,ICU4C其他部分也使用Locale 作为定制行为依据的ID。例如ICU中时间日期转换的服务是Locale相关的,它根据目标Locale的信息来转换时间日期,如果Locale是en_US(美国),一个星期的第一天会被表示成"Monday",而如果Locale 是zh_CN(中国),一个星期的第一天也应该被表示成"星期一"。 ICU4C的API(C++)使用类Locale来表示Locale,这个类提供了查询语言,国家和变量的方法;在基于C的API中,Locale 则被定义为简单的字符串。 Resource Bundle的实现 Resource Bundle是国际化中重要的数据查询机制,它的实现原理是将Locale相关的数据和程序代码分离,将数据和数据的表现采用 "键-翻译"形式映射。这样做的好处包括: (1) 程序代码中不会出现 和Locale相关的数据,程序员不需要了解或者使用目标Locale相关的语言数据。 (2) 需要翻译的数据可以直接拿给了解目标平台语言的专业人员翻译,而不需要提供代码。 (3) 数据统一集中,使得数据的管理更加方便。 ICU4C中提供了Resource Bundle的实现,并且ICU4C中的Resource Bundle功能更加强大,ICU4C中Resource Bundle的特性包括: 多样的数据类型支持:ICU4C中的Resource Bundle支持多种数据类型,包括:字符串,二进制文件(图片,文件等),数值,数组(Array),表(Table),甚至到其他资源的链接。字符串,二进制文件(图片,文件等),数值被称为简单数据类型;表(Table)和数组(Array)都是数据的集合,表储存具有名字的数据,数组储存没有名字的数据。 多样的数据查询方法:ICU4C提供了多种方法来查询Resource Bundle中的数据:表(Table)可以通过键(key),索引(index)和迭代 (iteration) 方式访问;数组(Array)可以通过索引 (index)或者迭代 (iteration) 方式来访问;字符串,二进制文件及数值这几种简单数据类型则可以通过键(key) 来访问。 优秀的数据回调机制:ICU4C的资源管理框架提供了优秀的数据回调机制。这个机制保证了当查询的数据资源不存在的情况下,ICU4C能自动找到相对最恰当的数据。回调通常会发生在以下两种情况: [1] 当某个Locale的资源文件被请求的时候,如果这个Locale相对的目标资源文件不存在,ICU4C的资源管理框架会自动回调,并且按照一定顺序查找更加适合的资源文件。例如,当请求Locale "zh_CN"相对应的资源文件时候,没有找到这样的资源文件,ICU4C会自动回调查找 Locale"zh"对应的资源文件,如果这个资源文件存在,将会返回这个资源文件;如果"zh"对应的资源文件还不存在,ICU4C将进一步回调。 [2] 当某个资源文件内部的数据找不到的时候,ICU4C会在相对通用的资源文件中查找。 例如,某一次数据查询,某一个资源数据没有能在Locale "en_IE_EURO"的资源文件中找到,继而ICU4C会去"en_IE"相对的资源文件中去查找相应的数据。 和XLIFF格式相互转换:XLIFF(XML Localisation Interchange File Format)本地化交换文件格式,XLIFF 是XML的一种应用,是用来在与翻译项目的各方之间交换本地化数据的格式,可以被用来作为中间文件格式来翻译多语言文档。ICU4C提供的工具可以将已有的Resource Bundle 转换为XLIFF格式,或者将已有的XLIFF格式文件转换成ICU4C的Resource Bundle资源文件。 Resource Bundle相关的ICU4C API中,C++ 平台下最重要的类是 ResourceBundle,这个类包含了和一系列特定Locale相关的资源信息,另外,程序员通过类的构造函数来打开相关Locale相对的资源文件。C语言相关的重要函数包括:ures_open用来打开对应Locale下的资源,ures_getByKey通过关键字方式查询,ures_getByIndex通过索引查询,ures_getNextResource通过迭代方式查询,ures_close关闭打开的Resource Bundle。 时间日期转换服务 正如第一章所述,时间的表示是由很多因素决定的,国际化过程中,软件内部的时间必须根据目标Locale和目标时区进行巧当转换之后呈现出来。ICU4C提供了完善的时间日期转换支持,用户可以通过使用ICU4C做到: (1) 根据不同时区转换时间表示。 (2) 解析时间字符串到ICU4C内部表示; 被解析的时间格式可以是任意的,因为ICU支持定制解析规则。 (3) 根据目标Locale,指定的格式,时区来格式化时间表示。 (4) 操作时间(如两个时间之间的比较,获得当前时间增加一天后的时间表示等) ICU4C的时间日期转换服务提供了丰富的API来支持这些功能,以C++平台下API为例,其中最重要的几个类包括: UDate:UDate用来存放ICU4C时间的内部表示,每个UDate是个 double类型的值,存放从GMT时间1970年1月1日24:00开始到被表示时刻经过的毫秒数;UDate表示的是时刻的概念,是个Locale,Time Zone 无关的概念,我们发现JAVA中的Date类同ICU4C种的UDate有类似的含义。 DateFormat:ICU4C提供了抽象类DateFormat来实现时间的格式化和解析操作,用户可以使用这个类来格式化时间和日期的内部表示或者用来解析已有的语言相关的时间/日期形式转换为内部表示。 Calendar:使用Calendar类可以实现时间在ICU4C的内部表示和"年月日"形式的相互转换。用户还可以使用这个类来实现时间相关的各种操作,如计算将已有时间基础上加两天时间的结果 TimeZone:TimeZone类是用来表示时区的抽象类,除了表示时区的偏移,TimeZone类还加入了夏令时的支持。Calendar需要设置TimeZone来生成目标时区的时间表示。 SimpleDateFormat: SimpleDateFormat是以语言独立的方式格式化,解析及标准化时间的具体类。用户可以使用SimpleDateFormat将UDate格式化成文本,或者将时间表示的文本转换成UDate形式。用户还可以使用这个类应用自定义的模式(Pattern)来定制解析或者格式化的规则。 数字,货币的格式化 数字在程序的内部表示是二进制形式的, 但是,将内部表示的数字呈现出来的时候还需要额外的注意。不仅仅是不同Locale影响数字表现方式,数字的类型也影响数字的表示。数字需要根据数字的类型以及目标的Locale进行格式化。 ICU4C提供了完善的数字、货币格式化能力,它支持多种类型的数字,包括西部数字,印度数字,和阿拉伯数字;同时,它还支持数字的多种形式,包括科学表达式如"1.23E4",百分率表达式如"12%",货币表达式如"$123"等。使用ICU4C,用户可以做到: (1) 根据特定Locale格式化数字内部表示到呈现表示。 (2) 将软件中的货币数字转换为特定Locale下的货币表示(包括货币特征的数字表示和货币符号)。 (3) 控制数字的显示。 (4) 以类似于函数printf对数字的格式化。 ICU4C的数字,货币格式化服务的API(C++)中最重要的类包括: NumberFormat:NumberFormat是个抽象类,它可以被用来根据某个Locale的实现对数字的格式化或者完成表示数字的字符串的解析,用户还可以使用NumberFormat来确定数字的类型,如百分率或者货币数字等;NumberFormat可以根据设置的类型输出数字格式化后的结果。 DemicalFormat:类DemicalFormat继承于NumberFormat,是用于十进制数字操作的类,程序员可以使用NumberFormat的createInstance方法获取DemicalFormat的实例;DemicalFormat包括了一系列的可以定制的符号(Symbol)和可以定制的模式(Pattern),符号和模式共同组成了数字格式化和解析的规则。 RuleBasedNumberFormat:RuleBasedNumberFormat也是NumberFormat的子类,它一般被用来将数字转换成拼写形式,如将数字25,3476 拼写成 "twenty-five thousand three hundred seventy-six",还可以被使用来将数字转换为时间表示等。同样,RuleBasedNumberFormat中的规则可以被定制来显示程序员想要的结果。 字符集的支持 由于软件平台对Unicode支持程度的区别,即使使用Unicode作为软件字符集,软件国际化过程中也经常会遇到非Unicode字符集支持的要求,文本常常需要在Unicode和非Unicode字符集中相互转换。ICU4C的强大在于它提供了500多种字符集的支持,并且有效的解决了字符集相关的问题,用户可以使用ICU4C做到: (1) 快速有效地完成单个字符或者字符串,或者字符流在不同编码集中的转换(包括Unicode和其他字符集的相互转换等)。 (2) 面向不同平台的字符转换结果保持一致。存在着这样的情况,同一个字符集,不同平台下的某些字符的编码也会不同,这会导致字符从一个平台切换到另一个平台下时存在数据丢失问题,ICU4C提供了有效机制保证了转换结果的一致性。 (3) 检测未知格式数据的字符编码方式。 (4) 在ICU4C中定制添加新的字符集支持。 (5) 可以为传输和存储需要压缩Unicode文本 字符集转换主要依靠API中提供的函数实现,这些函数被归纳在"ucnv.h"头文件中,其中最重要的几个函数包括: ucnv_open: 用于打开转换服务的函数,参数为目标字符集的名字,函数返回对应目标字符集的converter(转换服务);函数返回的converter可以作为参数传入其他函数做目标字符集相关的实际转换工作。 ucnv_fromUChars:ucnv_open返回的converter会作为参数传入这个函数,标示了目标字符集的类型。这个函数是将Unicode字符集下的字符串转换为目标字符集下的字符串。 ucnv_toUChars:同ucnv_fromUChars,区别在于ucnv_fromUChars将Unicode字符集下的字符串转换成其他指定的字符集字符串,ucnv_toUChars将指定的非Unicode字符集字符串转换为Unicode字符串。 ucnv_getNextUChar:同理,ucnv_open返回的converter会作为参数传入这个函数,标示目标字符集的类型。这个函数将使用Unicode编码的源字符串一个的一个字符转换到目标字符集下。函数每被调用一次,只有一个Unicode字符将会转换,同时指示被转换字符的指针往后移一个Unicode字符。 ucnv_close:ucnv_open返回的converter会作为参数传入这个函数,作为函数操作的对象,这个函数关闭了由ucnv_open打开的converter(转换服务)。 消息的格式化 消息是一系列字符串,数字和日期数据的组合,软件常常需要输出些动态消息,国际化中如何让这些消息以正确合理的语言格式显示是个问题。ICU4C提供了格式化消息的功能,用户可以使用ICU4C做到: (1) 不需要给每种Message都提供对应Locale的版本,只需要定制字符串,数字,日期的排列模式,通过应用Resource Bundle 获取某些字符串的确切翻译,就可以在指定Locale 下获得正确合理的消息文本。 (2) 可以通过用户定义的模式(Pattern)来解析已有的字符串。 (3) 本地化工作者也同样可以修改消息的内容,消息格式以及文本的排列顺序。 ICU4C消息格式化的API(C++)有两个重要的类,分别是MessageFormat和ChoiceFormat,下面是对这两个类的解释: MessageFormat: ICU4C使用MessageFormat类来组成针对终端客户的符合语言逻辑的消息,它将消息组成的元素(包括字符串,数字,日期等)按照用户指定的模式组合起来。通过和Resource Bundle合作,用户可以利用MessageFormat获得在任意指定Locale下任意格式的合乎语言逻辑的消息输出。 ChoiceFormat: ChoiceFormat是继承于NumberFormat的类,可以用作MessageFormat的补充。通过ChoiceFormat类可以支持复数,数字范围等。 字符串处理 使用Unicode字符集作为软件字符串内部字符集并不能避免字符串处理的问题,使用ICU4C,用户可以实现以下的字符串操作: (1) 大小写映射:大小写映射是用来处理语言中存在的字母大小写及字母的标题表示的问题。即使是使用相同的字母表,不同Locale同一字母的大(小)写或者标题表示却可能不同。ICU4C给大小写映射提供了强大的支持,ICU4C支持3种方式的字母操作,分别是:常规字母映射;语言相关的字母映射;字母大小写表示(大写,小写,标题表示)擦除。 (2) 标准化:转换已有的文本到一个同一等价形式的过程被称为标准化。标准化后的文本可以方便搜索,查询等进一步的字符串操作。ICU4C提供了Normalizer类实现了字符串的标准化操作,Normalizer类可以看成两个部分,它一方面用于标准化字符串及测试目标字符串是否已经被标准化的静态方法;另一方面,它还可以作为任何类型文本的标准化形式的迭代器 (iterator)。 (3) 音译:音译是字符串从一种语言到另一种语言的转换中比较通用的一种方式,音译不同于翻译,它使用目标语言给出源语言字符串的音译,而并不对字符串进行意义上的翻译。例如清单4是日语到拉丁语的音译。 清单4 音译  (4) 字符串整理 用户常常期望能看到经过合理排序后的字符串,因为经过合理排序的字符串更便于有效查找期望的数据。但是"排序"的概念对于不同语言是不同的;即使使用相同字母集的语言,"排序"的概念也可能不同;即使在同一语言中,不同用途的文档中字符串的"排序"概念也会不同。 "排序"概念的区别引起国际化中字符串整理的问题,ICU4C实现了和UCA(Unicode Collation Algorithm)全面兼容的Unicode字符串整理服务,它给用户需要的各种Locale都提供了适合的字符串排序方法。 ICU4C的字符串整理服务提供了两部分的内容:字符串的比较及字符串"比较键"的生成。字符串的"比较键"是从原Unicode字符串中计算出来的,代表原被计算Unicode字符串的,由 '\0' 结束的字符串,它可以直接被用于标准C中的strcmp, memcmp 等函数来比较原字符串。ICU4C的API(C++平台)中提供了Collator类来实现Unicode字符串的整理功能。 (5) 边界检查 应用程序在处理文本的时候常常会遇到文本边界的问题,字符串的边界检查是指确定文本的边界,文本的边界包括字母分界,字分界,句子的分界及段落的分界。 不同Locale定义的分界有区别,软件国际化中不能以本地Locale来假设文本的边界。 ICU4C提供了API(C++)BreakIterator类来实现Unicode字符串的边界检查。 结束语 在本篇文章中,我们讨论了国际化中常见的问题,介绍了C/C++平台国际化开发组件ICU4C,并且概要介绍了ICU4C的特性和强大的国际化支持能力。可以看到ICU4C的强大,在于它对国际化的支持是广泛而且深入的,用户几乎可以使用ICU4C解决任何C/C++平台下软件国际化的问题。后面的文章将更加详细地描述ICU4C这个强大的国际化开发组件。 原文:http://www.ibm.com/developerworks/cn/opensource/os-icu4c/ 转载请保留固定链接: https://linuxeye.com/Linux/icu4c.html |