当解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode)。Opcode cache的目地是避免重复编译,减少CPU和内存开销。如果动态内容的性能瓶颈不在于CPU和内存,而在于I/O操作,比如数据库查询带来的磁盘I/O 开销,那么opcode cache的性能提升是非常有限的。但是既然opcode cache能带来CPU和内存开销的降低,这总归是好事。 现代操作码缓存器(Optimizer+,APC2.0+,其他)使用共享内存进行存储,并且可以直接从中执行文件,而不用在执行前“反序列化”代码。这将带来显着的性能加速,通常降低了整体服务器的内存消耗,而且很少有缺点。 为什么要使用Opcode缓存? 这得从PHP代码的生命周期说起,请求PHP脚本时,会经过五个步骤,如下图所示:  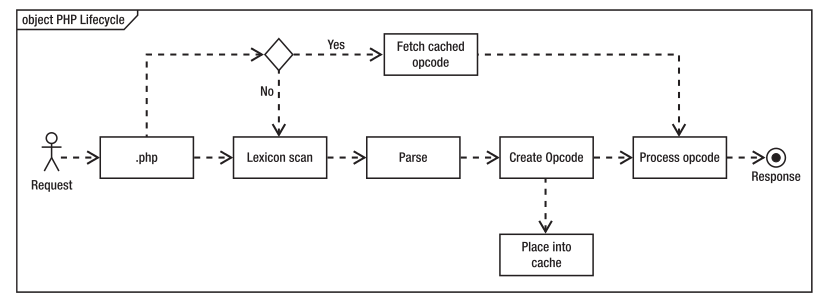 有那些PHP opcode缓存插件? Optimizer+(Optimizer+于2013年3月中旬改名为Opcache,PHP 5.5集成Opcache,其他的会不会消失?)、eAccelerator、xcache、APC ... PHP opcode原理: Opcode是一种PHP脚本编译后的中间语言,就像Java的ByteCode,或者.NET的MSL,举个例子,比如你写下了如下的PHP代码: <?php echo "Hello World"; $a = 1 + 1; echo $a; ?>PHP执行这段代码会经过如下4个步骤(确切的来说,应该是PHP的语言引擎Zend) 1.Scanning(Lexing) ,将PHP代码转换为语言片段(Tokens) 2.Parsing, 将Tokens转换成简单而有意义的表达式 3.Compilation, 将表达式编译成Opocdes 4.Execution, 顺次执行Opcodes,每次一条,从而实现PHP脚本的功能。题外话:现在有的Cache比如APC,可以使得PHP缓存住Opcodes,这样,每次有请求来临的时候,就不需要重复执行前面3步,从而能大幅的提高PHP的执行速度。 那什么是Lexing? 学过编译原理的同学都应该对编译原理中的词法分析步骤有所了解,Lex就是一个词法分析的依据表。 Zend/zend_language_scanner.c会根据Zend/zend_language_scanner.l(Lex文件),来输入的 PHP代码进行词法分析,从而得到一个一个的“词”,PHP4.2开始提供了一个函数叫token_get_all,这个函数就可以讲一段PHP代码 Scanning成Tokens; 如果用这个函数处理我们开头提到的PHP代码,将会得到如下结果:
Array
(
[0] => Array
(
[0] => 367
[1] => Array
(
[0] => 316
[1] => echo
)
[2] => Array
(
[0] => 370
[1] =>
)
[3] => Array
(
[0] => 315
[1] => "Hello World"
)
[4] => ;
[5] => Array
(
[0] => 370
[1] =>
)
[6] => =
[7] => Array
(
[0] => 370
[1] =>
)
[8] => Array
(
[0] => 305
[1] => 1
)
[9] => Array
(
[0] => 370
[1] =>
)
[10] => +
[11] => Array
(
[0] => 370
[1] =>
)
[12] => Array
(
[0] => 305
[1] => 1
)
[13] => ;
[14] => Array
(
[0] => 370
[1] =>
)
[15] => Array
(
[0] => 316
[1] => echo
)
[16] => Array
(
[0] => 370
[1] =>
)
[17] => ;
)
分析这个返回结果我们可以发现,源码中的字符串,字符,空格,都会原样返回。每个源代码中的字符,都会出现在相应的顺序处。而,其他的比如标签,操作符, 语句,都会被转换成一个包含俩部分的Array: Token ID (也就是在Zend内部的改Token的对应码,比如,T_ECHO,T_STRING),和源码中的原来的内容。接下来,就是Parsing阶段了,Parsing首先会丢弃Tokens Array中的多于的空格,然后将剩余的Tokens转换成一个一个的简单的表达式 1.echo a constant string 2.add two numbers together 3.store the result of the prior expression to a variable 4.echo a variable然后就改Compilation阶段了,它会把Tokens编译成一个个op_array, 每个op_arrayd包含如下5个部分: 1.Opcode数字的标识,指明了每个op_array的操作类型,比如add , echo 2.结果 存放Opcode结果 3.操作数1 给Opcode的操作数 4.操作数2 5.扩展值1个整形用来区别被重载的操作符比如,我们的PHP代码会被Parsing成: * ZEND_ECHO 'Hello World' * ZEND_ADD ~0 1 1 * ZEND_ASSIGN !0 ~0 * ZEND_ECHO !0你可能会问了,我们的$a去那里了? 这个要介绍操作数了,每个操作数都是由以下俩个部分组成: a)op_type : 为IS_CONST, IS_TMP_VAR, IS_VAR, IS_UNUSED, or IS_CV b)u,一个联合体,根据op_type的不同,分别用不同的类型保存了这个操作数的值(const)或者左值(var)而对于var来说,每个var也不一样 IS_TMP_VAR, 顾名思义,这个是一个临时变量,保存一些op_array的结果,以便接下来的op_array使用,这种的操作数的u保存着一个指向变量表的一个句柄(整数),这种操作数一般用~开头,比如~0,表示变量表的0号未知的临时变量 IS_VAR 这种就是我们一般意义上的变量了,他们以$开头表示 IS_CV 表示ZE2.1/PHP5.1以后的编译器使用的一种cache机制,这种变量保存着被它引用的变量的地址,当一个变量第一次被引用的时候,就会被CV起来,以后对这个变量的引用就不需要再次去查找active符号表了,CV变量以!开头表示。 这么看来,我们的$a被优化成!0了。 参考:http://www.laruence.com/2008/06/18/221.html 转载请保留固定链接: https://linuxeye.com/Linux/1930.html |